Kaggle Titanic やってみた感想
データサイエンスの一連の流れってどんな感じなんだろう?と体験して見るために、Kaggleのチュートリアルをやってみた。
https://www.kaggle.com/c/titanic
Kaggle Titanic は、Kaggle のチュートリアルでよく使われる題材。タイタニック号の乗客名簿と、生存できたかを含むデータを与えられ、予測モデルを作成し、その精度を競う。
データをダウンロードする
- https://www.kaggle.com でユーザー登録をする。
https://www.kaggle.com/<username>/accountにアクセスし API => Create New API Token から kaggle.json をダウンロード- ダウンロードしたアクセストークンを ~/.kaggle/kaggle.json に置く
以下 pipenv を使った例
$ pipenv install kaggle $ kaggle competitions download -c titanic
これで train.csv と test.csv のデータが手に入る。test.csv は解答用で、生存できたか(Survived)のデータは含まれない。
大雑把な流れ
- 欠損値の処理(今回は単に捨てた)
- 値の正規化(年齢など)
- train.csv のうち 80% を訓練用、20% をテスト用データとして分割
- 訓練モデルを作成
- 訓練モデルにテストデータを入力し、精度を測定
今回は kaggle への提出は行っていない。
keras によるモデル作成
https://github.com/linxinzhe/tensorflow-titanic/blob/master/keras_titanic.py を参考に、理解するためにリファクタしてみた。
from keras.optimizers import SGD, Adam from keras.layers import Dense, Activation from keras.models import Sequential from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import LabelEncoder import numpy as np import pandas as pd def normalize_data(data): not_concerned_columns = ["PassengerId", "Name", "Ticket", "Fare", "Cabin", "Embarked"] data = data.drop(not_concerned_columns, axis=1) data = data.dropna() # normalize dummy_columns = ["Pclass"] for column in dummy_columns: data = pd.concat([data, pd.get_dummies( data[column], prefix=column)], axis=1) data = data.drop(column, axis=1) # normalize Label:Sex to int le = LabelEncoder() le.fit(["male", "female"]) data["Sex"] = le.transform(data["Sex"]) # normalize Age ss = StandardScaler() data["Age"] = ss.fit_transform(data["Age"].values.reshape(-1, 1)) return data def split_train_and_test(data, rate=0.8): data_y = data["Survived"] data_x = data.drop(["Survived"], axis=1) train_valid_split_idx = int(len(data_x) * rate) train_x = data_x[:train_valid_split_idx] train_y = data_y[:train_valid_split_idx] valid_test_split_idx = (len(data_x) - train_valid_split_idx) // 2 test_x = data_x[train_valid_split_idx + valid_test_split_idx:] test_y = data_y[train_valid_split_idx + valid_test_split_idx:] return train_x.values, train_y.values.reshape(-1, 1), test_x.values, test_y.values.reshape(-1, 1) def build_model(input_dim): model = Sequential() model.add(Dense(20, input_dim=input_dim)) model.add(Activation('relu')) model.add(Dense(1, input_dim=20)) model.add(Activation('sigmoid')) model.compile(optimizer=SGD(lr=0.01), loss='binary_crossentropy', metrics=['accuracy']) return model # load data train_data = pd.read_csv("data/train.csv") normalized_data = normalize_data(train_data) train_x, train_y, test_x, test_y = split_train_and_test(normalized_data, 0.8) model = build_model(train_x.shape[1]) # train model.fit(train_x, train_y, nb_epoch=120, batch_size=16) # test [loss, accuracy] = model.evaluate(test_x, test_y) print("loss:{0} -- accuracy:{1}".format(loss, accuracy))
だいたい 80~86%ぐらいの予測率だった。他のチュートリアルを見てもそのぐらいに収束するっぽい。 competition で100点だしてる人たちは、答えをなんやかんややってチートしてそう。
感想
- あんまり綺麗なコード例が見つからない。今回の題材は、チュートリアルなのに、コードを綺麗に見せようという努力がなされたものを見かけなくてイライラした。
- jupyter notebook でやる人が多いのか、数行のスニペット単位で整形することが多く、プログラマ的なモジュール分割ではない、という印象を受けた
- 卒論でR触ってたのでpandas のデータフレームなんとなくわかったが、各種utility が覚えゲーっぽい
- 今回は単に欠損値を捨てたが、中間値で埋めたり、それ自体に予測モデルを作って埋める人が見受けられた。中間値それ自体がバイアスになったり、あるいは欠損値があることそのものがある種の特徴量になってる場合、どう扱うべきか、コンテキストごとに迷いそう
- 出先でやっていたが、バッテリ消費が激しい
- 一応、このデータでは「女・子供は助かる可能性が高い」というのは知っていたのだが、ディープラーニングを使うとその事実に気づくことなくモデルができてしまうので、ドメイン的な学び甲斐がなかった。NNのバイアスから結果に響かない特徴量を検出して捨てる、みたいな手法はありそうなので調べる
実践: React Hooks
hooks が発表されてから趣味でも現場でもずっと hooks を使っています。おかげでだいぶこなれてきて、だいたいなんのライフサイクルでも表現できるようになってきました。
最初は単に useState が state を、 useEffect が componentDidMount/componentDidUpdate を置き換えるもの、と説明を済ますつもりでしたが、 useEffect についてはライフサイクルのモデルがぜんぜん違うので、別の説明をする必要があるように感じていました。
で、その結果 React Hooks を理解するには、関数のメモ化を理解するのが最も簡単だと思ったので、その説明をしつつ、イディオムを解説していこうと思います。
最初に: React Hooks は何であり、何ではないか
関数コンポーネントが状態を持てるようにするもので、関数のメモ化のテクニックを多用します。
redux を置き換えるものではない。が… Redux の機能を一部吸収しています(useReducer)。後述する Context と組み合わせることで、middleware なし Redux が簡単に実現できます。
直接的には recompose や HOC といったテクニックを置き換えるものです。
メモ化されたライフサイクル
(メモ化関数についての基本的な説明をするので、わかってる人は読み飛ばしてください)
const fib = n => n < 2 ? n : fib(n - 1) + fib (n - 2); fib(10) // 55
この fib(10) は、計算の定義自体は簡単ですが、実際には何度も同じ値への計算をすることになります。 これを効率よく計算するため、計算済みの値は保存してしまうこととしましょう。
この fib 関数をメモ化するとこんな風になります。
const memo = [0, 1]; // js の配列のインデックス外へのアクセスの雑な挙動を利用 const fib = n => { if (memo[n] != null) return memo[n]; const r = fib(n - 1) + fib (n - 2); return memo[n] = r; }
これで、 fib(n) が計算済みだったら、計算済みの値を返す、という挙動になります。
ちなみに、 lodash の _.memoize を使って const fib = _.memoize(n => n < 2 ? n : fib(n - 1) + fib (n - 2)); でもメモ化できます。
React Hooks でのメモ化
React Hooks を活用するには、このメモ化の仕組みを理解しておく必要があります。
React Hooks の、特に useEffect と useCallback の第二引数は、このメモ化の理解を必要とします。
function Foo({x}) { useEffect(() => console.log('x changed'), [x]); return <div>{x}</div> }
これは Foo への props x が書き換わるごとに、useEffect が実行されます。 useEffect(fn, memoizedKeys) の fn は、 memoizedKeys ごとにメモ化されている、と言えます。ただし、全ての状態をメモ化しているのではなく、直前の状態だけをメモしています。
ここではメモ化のヒントは 配列になっています。一致判定のロジック自体は配列の各要素の shallow equal、雑に言ってしまうと newKeys.every((k, i) => k === oldKeys[i]) です。
差分検知に失敗するケース
useCallback は memoizedKeys でメモ化された関数を返却します。もし、 memoizedKeys が一致する場合、新しい関数は生成されません。前のステップで生成された関数をそのまま返却します。
x+y が表示され、クリックすると、x+y を console.log する、というコンポーネントで考えてみましょう。
function Sum({x, y}) { const onClick = useCallback(() => console.log('x,y changed', x + y), [x]); return <div onClick={onClick}>{x + y}</div> }
このとき、新しい関数が生成されるのは、 x が変更されるときだけなので、y の更新には反応しません。なので、y だけ更新した際は、表示は更新されても、新しい x と 古い y を足した値を console.log することでしょう。
正しく両方の値に反応したい場合、次のように [x, y] と memoizedKeys を与える必要があるわけですね。
function Sum({x, y}) { const onClick = useCallback(() => console.log('x,y changed', x + y), [x, y]); return <div onClick={onClick}>{x + y}</div> }
より一般化すると、「関数クロージャの中で参照する要素はすべて memoizedKeys に列挙する」というベストプラクティスになると思います。
ちょっとむずかしいですが、総じて、差分アルゴリズムに由来する React らしい、一貫した副作用の抽象化と言えるでしょう。
実行コンテキストの仕組み
見た目上は魔法のように見える Hooks の記法ですが、単に副作用が外出しされているだけです。最初は algeblaic effects が云々みたいな話がありましたが、その話は忘れてください。
中で何が起こっているかは、すごく雑な疑似コードを書くと、たぶんこんな感じだと思います。
// 実行コンテキスト const hooksMap = {} // ReactDOM.render の中の差分更新のどこか const hooks = hooksMap[oldElement.id] || [] const newElement = updateElement(oldElement, virtualElement, hooks); hooksMap[newElement.id] = newElement.hooks;
hooks に実行インスタンスを引っ掛けてコンテキストを生成しているだけです。
より詳しい実装を知りたければ、こちらの翻訳記事を参照してください
(翻訳) React Hooks は魔法ではなく、ただの配列だ
イディオム
componentDidMount/componentWillUnmount 相当
import React, { useEffect } from 'react' function Foo() { useEffect(() => { console.log('mounted') return () => { console.log('unmount') } }, []) return <></> }
state を持つ
import React, { useState } from 'react' function Foo() { const [state, setState] = useState([]) return ( <> {state.map(i => <div key={i}>i</div>)} <button onClick={ ()=> setState([...state, Math.random().toString()]) }> add </button> </> ) }
ref を使って DOM を触る。(textarea にフォーカスする例) DOMへ起きた副作用を検知する場合は useEffect ではなく useLayoutEffect になります。
import React, { useState } from 'react' function Foo() { const textareaRef = useRef(null); useLayoutEffect(() => { if (textareaRef.current) { textareaRef.current.focus() } }, []) return <textarea ref={textareaRef}/> }
外部の副作用を監視して、プログレスバーを進める、みたいな例
import React, { useState, useEffect } from 'react' function Foo() { const [step, setStep] = useState(0); useEffect(() => { // 何か外部の副作用 const unsubscribe = resouce.subscribe(() => { setStep(step + 1); }); return () => unsubscribe() }, [step]) return <></> }
useReducer + context = redux like
useReducer は react で公式に reducer の仕組みが取り込まれたものです。これは単に、state の reducer 版イディオムでしかありません。
これに、親子の間で暗黙に値を受け渡す Context API と、useContext の hooks を使うと、次のように redux 風の flux が再現できます。
import React, { useReducer, useContext, Dispatch, ReactElement } from "react"; import ReactDOM from "react-dom"; type CounterState = { count: number; }; const initialState: CounterState = { count: 0 }; function reducer(state: CounterState, action: any) { switch (action.type) { case "reset": { return initialState; } case "increment": { return { count: state.count + 1 }; } case "decrement": { return { count: state.count - 1 }; } default: { return state; } } } // Container const CounterContext = React.createContext<CounterState>(null as any); const DispatchContext = React.createContext<Dispatch<any>>(null as any); function App({ initialCount }: { initialCount: number }) { const [state, dispatch] = useReducer(reducer, { count: initialCount }); return ( <CounterContext.Provider value={state}> <DispatchContext.Provider value={dispatch}> <Counter /> </DispatchContext.Provider> </CounterContext.Provider> ); } // Connected component function Counter() { const state = useContext(CounterContext); const dispatch = useContext(DispatchContext); return ( <div> Count: {state.count} <button onClick={() => dispatch({ type: "reset" })}>Reset</button> <button onClick={() => dispatch({ type: "increment" })}>+</button> <button onClick={() => dispatch({ type: "decrement" })}>-</button> </div> ); } ReactDOM.render(<App initialCount={2} />, document.querySelector(".root"));
ただし、useReducer はだいぶ redux のそれと比べて、store 層が簡略化されています。middleware の仕組みは一切ありません。
reducer 定義自体は、単に (state, action) => state を守っていればいいです。 redux.combineReducers をヘルパとして使ってもいいですし、redux で使っていた reudcer をそのまま置き換えることも可能です。
とりあえず useReducer + Context で作ってみて、複雑な Middleware が必要だったら Redux を使う、という感じでいいんじゃないでしょうか。
どう適応するか
現状、表現力という点で、関数コンポーネントとクラスコンポーネントはほぼ同等です。
class MyComponent extends React.Component といったクラス記法は、おそらく推奨されなくなるのではないでしょうか。消えることはないでしょうが、推奨されない、といった雰囲気です。
React は関数型プログラミングの雰囲気が強いコアチーム、出自(facebook)、コミュニティなので、おそらく今後見かけるコードは hooks がメインになる気がします。
これは勝手な憶測ですが、React は、頭がいいであろう Facebook のエンジニアがメインターゲットなので、頭が良い人しかターゲットにしていない、というのがたぶんあって、僕はそれが好きではあるんですが、 Vue に初心者層をかっさらわれたのはそういう姿勢に問題があったんじゃないか、という気持ちもあります。
何にせよ、シンプルな一貫したアルゴリズムを理解していれば、すべてがうまくいく、という世界観で、自分はそこが気に入っています。
GIGAZINE が音声認識アプリのマニュアルを書いてくれた
先日作ったこれです recording-studio.netlify.com
いつもだったらこういうの紹介しないんですが、GIGAZINEさんがRecording Studio(仮。なんか適当に名前をつける必要があった)の紹介記事を書いてくださり、アプリ紹介のついでで、僕が面倒で書かなかったアプリの使い方のドキュメントまで詳しく書いてくださっています。リテラシー高い人しか使えない状態だったので、ありがたいです。
自分で読んでみると、たしかにマイクのパーミッションとか開始・終了とか暗黙的でしたね…
いろいろ機能追加を考えてたんですが、これ自体は小さくまとまって完成してるので、ドキュメントを古くしないよう、新しくつくるにしても別ドメインにしようと思います。
ブラウザでマイク入力から書き起こしを行うツールを作った
Chrome でマイクからの音声を録音して、その音声認識で書き起こしも同時に行うツールを作った。
recording-studio.netlify.com で遊べる。
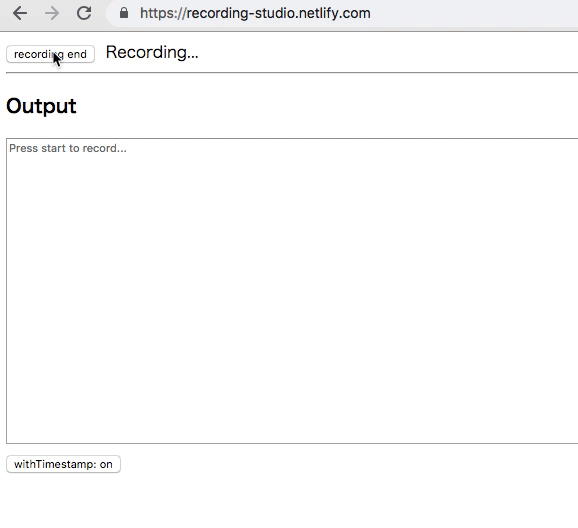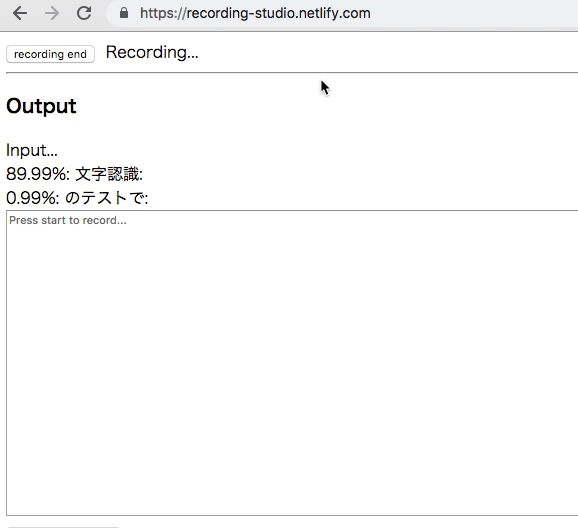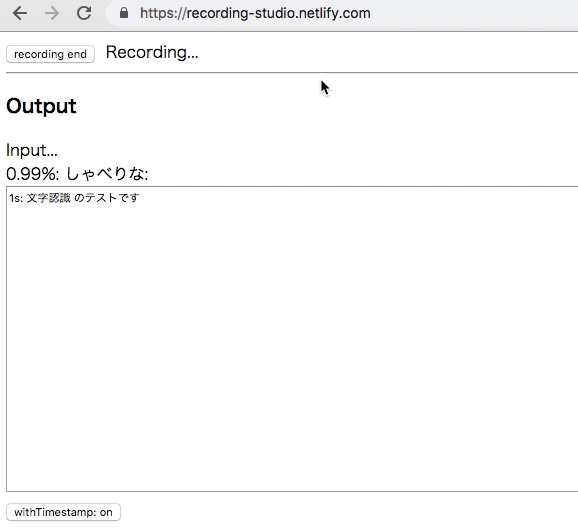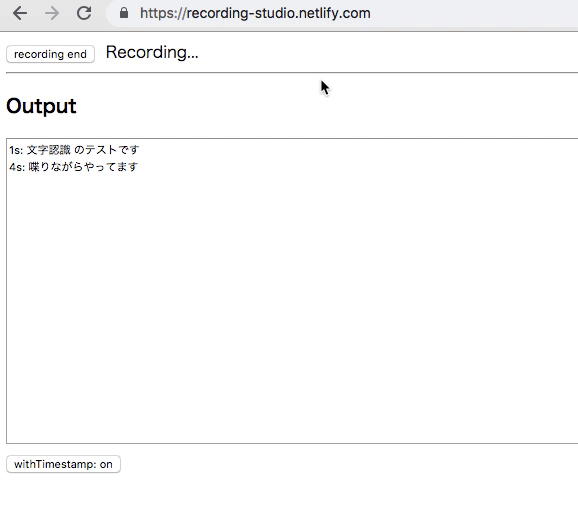
Chrome に搭載されてる Web Standard Proposal? の SpeechRecognition API を使っている。
Chrome のみだが、 PC Chrome だけではなく Android Chrome でも動作確認済み。
ブラウザをオフラインにすると動作しないので、このAPI の 中身はたぶん Google Speech to Text API だと思われる。
出力
録音したものは webm ファイルとしてダウンロードできる。認識されたテキストも、タイムスタンプ付きのプレーンテキストなので、適当にもっていって、ぐらいの気持ち。
クラウドで音声認識してることを除けば、どこかにアップロードしてるわけではない。インメモリに貯めて、そのデータを吐いてるだけ。
実はFirebase Storage にアップロードする版も作ったのだが、音声をホスティングするサービスの見積もりをした結果、個人で運用できるものではない、という判断になった。自分専用の Podcast ツールとして使うかも。
将来性
Google Speech to Text API は基本的に有料APIだが、これを通して使うと無料。
Web 標準のプロポーザルの顔をしてるがが Web標準になる気はしない。これを開発できるプレーヤは大手ベンダに限られるので、これを標準と言い張るのは邪悪ムーブな気がする。モデルが公開されていれば別だが…
とはいえ、とりあえず無料で遊べる内に遊んどこうというモチベーション。
今 Web DB Press でインタビュー企画を持ってて、書き起こしを依頼してるんだけど、その助けになるかなぐらいの気持ちもあり、作った。
Markdown コードブロックの JavaScript を bundle して実行するエディタを作ってみた
ペライチの markdown のコードブロックをビルドして iframe の中で実行できる
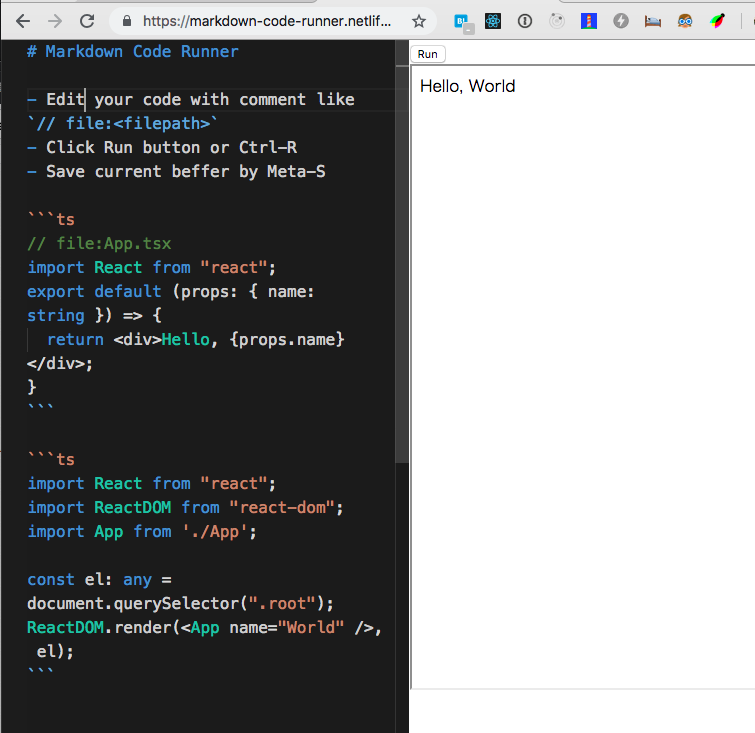
https://markdown-code-runner.netlify.com で遊べる。
前々から作れるなと思っていたので作ってみた。3時間ぐらいかかった。
仕組み
- monaco-editor でコード編集
- remark で codeblock の AST を収集
- rollup と rollup-plugin-virtual でインメモリ上に依存を構築して bundle
- iframe でクロスドメイン制約を与えた状態で実行(
ifram.sandbox="allow-scripts")
外部からの入力受け取れないし、そもそも自動実行できないのでコード実行とはいえセキュリティ要件はそこまで厳しくないはず
TODO
- 実験的に React だけ特別扱いしてるが npm 対応したい
- monaco の補完用の worker がうまく起動してないので修正する
- browserfs 対応
- TypeScrpit のコード診断
- prettier 対応
- worker 対応
- というか https://markdown-buffer.netlify.com 上に実装
2018年良かった漫画・ゲーム
漫画
 (IKKI COMIX)")
- 作者: 林田球
- 出版社/メーカー: 小学館
- 発売日: 2018/11/12
- メディア: Kindle版
- この商品を含むブログを見る
ずっとよみたかったが kindle 版が発売されたのと、また完結したということで
")
- 作者: 小林有吾,上野直彦
- 出版社/メーカー: 小学館
- 発売日: 2015/04/30
- メディア: コミック
- この商品を含むブログ (3件) を見る
サッカーユースの話
 (アフタヌーンコミックス)")
- 作者: 真刈信二,DOUBLEーS
- 出版社/メーカー: 講談社
- 発売日: 2017/07/21
- メディア: Kindle版
- この商品を含むブログ (2件) を見る
江戸時代、日本の傭兵がヨーロッパに渡って、30年戦争の中で仇(?)を追う話。
 (ビッグコミックススペシャル)")
デッドデッドデーモンズデデデデデストラクション (1) (ビッグコミックススペシャル)
- 作者: 浅野いにお
- 出版社/メーカー: 小学館
- 発売日: 2014/09/30
- メディア: コミック
- この商品を含むブログ (75件) を見る
やたら弱っちい宇宙人に侵略される話。浅野いにお苦手だったが、サブカルちらしてはいるもののいつもと違うサブカルちらしかただったので、読みやすかった
 (アフタヌーンコミックス)")
- 作者: 山口つばさ
- 出版社/メーカー: 講談社
- 発売日: 2017/12/22
- メディア: Kindle版
- この商品を含むブログを見る
 (馬頭図書)")
- 作者: 野村亮馬
- 発売日: 2018/07/06
- メディア: Kindle版
- この商品を含むブログ (1件) を見る
SF。最近売れてる天国大魔境に雰囲気近いかも
 (アフタヌーンコミックス)")
- 作者: 桑原太矩
- 出版社/メーカー: 講談社
- 発売日: 2016/11/07
- メディア: Kindle版
- この商品を含むブログ (3件) を見る
ちまちま増えてきた異世界グルメもの。龍を捕まえて食べる話
")
- 作者: 高浜寛
- 出版社/メーカー: リイド社
- 発売日: 2016/01/29
- メディア: Kindle版
- この商品を含むブログ (2件) を見る
文明開化直後の長崎の貿易商の話。全然関係ないが地元が舞台なので土地勘わかって面白かった
ゲーム
- Slay the Spire
- Oxygen Not Included
- Caves of Qud
- Into the Breach
- Path of Exile
- Lucah: Born of a Dream
- ドキドキ文芸部
- ゼルダの伝説: BoW
個人的なゲームオブザイヤーは Slay the Spire 。そういえばこの記事書いてから1年が経った。
当時、全然無名だったが、思えば遠くまで来た。デッキ構築型ローグライクのフォロワーも増えてきて、これからまたジャンルとして一つ花開くんじゃないだろうか。
Into the Breach や Slay the Spire のような、ゼルダのようなAAAタイトルのオープンワールドの真逆というか、ある種のミニマリズムを突き詰めてメカニクスを探求するタイプのゲームが増えてきて、ワクワクしている。ボドゲからの逆輸入というか
プログラマという現代の傭兵
エンジニアの転職とかプログラミング教育周りで考えていたこと。
フランス革命と技術のコモディティ化
最近フランス革命やナポレオン戦争やナショナリズム、そしてクラウゼヴィッツの戦争論などを調べたりしていたんだけど、傭兵や専門技術の扱いについて、示唆的なものが多かった。
当時の傭兵は、扱いが難しかった大砲・銃火器を扱う専門集団で、技能職でもあった。それが 18 世紀になり火器の改良が進み、産業革命で効率的な生産が可能になり、そしてナポレオンによる国民軍の創設、そのヨーロッパにおける戦果によって、傭兵はその役割を終えた。
「傭兵はすぐ逃げる」というのが定説だが、彼らは金で動く専門職なので、負ける側に付く理由がないので、当然とも言える…特に戦争という、敗者の支払いが期待できない場では。そして彼らを雇う王侯貴族の経済力が、そのまま軍団の動員力に直結した。常備軍を持たない分、平時のコストも安くついた。
ナポレオン(と彼を分析したクラウゼヴィッツ)は、前線を支える兵士の士気を、愛国心に求めた。銃火器の扱いが平易になったこと、そして(職業軍人と比較して)高度な訓練を必要としない歩兵の運用のメソッドが確立したことで、それが可能になった。
そして、徴兵によって「自分で自分の国を守る」という意識変革を経た結果、貴族階級の存在理由が否定され、王権と封建制度を中心とした古い体制、アンシャンレジームが破壊されて、「国民国家」の現代に至る。
双方引かない国民国家同士の戦争が、いかに悲惨な消耗戦になるかは、第一次世界大戦、第二次世界大戦で明らかとなったわけだが…。
一方、現代では
この話は、本質的には、銃火器の取扱いの平易化という変化が、下部構造の柔軟性を生んだ話だと思っている。ナポレオンのすごいところは、その時代の変化を見逃さず適した組織を作り、軍事的優位を作ったところにある。結果としてナポレオンが敗北した理由も、ナポレオンに対抗するために追い込まれた側がそのメソッドを採用して反撃したところにあるわけで…。
翻ってプログラミング技術について考えると(この話の展開っておっさん臭くて嫌なんだが)…自分は、現代の銃火器は、プログラミング技術なんじゃないかと思っている。しかも、銃火器は戦場でしか役に立たないが、プログラミング技術は日常のあらゆる場面で役に立つ、可能性がある。
プログラミング技術は、個々人がネットワークに接続し、その計算リソースを借りてその能力を拡張するための手段だ。物事を議論の余地がないほどに小さいステップに分解するという、ある種非人間的な訓練を要求される。そして、この訓練メソッドが十分に成熟していない。
コモディティ化しないプログラミング技術
現在のプログラミング技術を取り巻く環境は、銃火器の取扱いが平易になる前のコモディティ化以前の傭兵全盛時代だと思っている。その理由はいくつかあって…
- 教育による能力の再現性がない
- 優秀なプログラマが教育によって育つ例がない
- システム側(社会)による受け入れ体制が整っていない
- プログラミング技術自体が(歴史が浅いので)進化し続けている
その結果、勝手に育った一部の人間が、プログラマに金を出してくれる会社に集まっている、という状態にある。ITの大手にいる人達は、10年前とそう変わらない。
会社の隆盛も早く、終身雇用を前提することが不可能で(日本社会の終身雇用自体が信用できなくなったのもあるが)、誰もが 10 年後にこの会社にいないと思っている。10 年前と変わったのが、コンピューターサイエンスで優秀な成績を修めたアカデミックエリートが、GAFA に行くようになったぐらいか。
個人としての最適と、社会としての最適が異なるのは前提として、自由度が高いコマとして競争力を持つことが、個人としての最適戦略になっている。少なくとも自分はそう思って動いている。
プログラミング教育について
本質的にプログラミング能力とは、物事の細かいステップへの分解能力と、何らかのルール制約下(プログラミング言語の表現力)での対応を発見することにあると思っている。
というのを前提として、国がプログラミング教育を推進したい気持ちもよく分かる。プログラミング教育を否定する人も、論理的思考力を鍛えることが大事、までは同意が取れると思う。従来、それは数学が担っていた分野だが、プログラミングは、数学教育メソッドの伝統的な制約から踏み出さないと訓練できない領域を多分に含むので、プログラミング教育という分野が創出された、という理解をしている。
それに対し、今のプログラマが育つ環境のリアルは、親方が弟子に伝授するという中世のギルド制度に近いのではないか、というのが界隈を見渡した際の予想としてある。親方は大学の教授かもしれないし、最初に入った会社のメンターかもしれないし、Twitter の強い友人かもしれない。どういう親方に技術を学んだかによって、その人の方向性が決まってしまうところが大きい。
ギルド制とはいえ、あんまり堅苦しくないのは、ハッカー文化は MIT の原始共産制っぽいヒッピー文化に強く影響を受けていて、自由を得るための実力主義社会という側面が強い(GNU や OSS)。ただし圧倒的に実力主義なので、実力がないと発言権がない。強者の論理であるとも思う。
プログラミング技術がコモディティ化するときは、ハッカー文化が失われるときであるとも思う。
終わり
こういう記事を書いといて何だが、何が正しいとか、何が正しくないとか言うつもりはない。自分は業界をそういう目で見ている、という話。
現実問題、たぶん、今大規模なサイバー戦争が起きたら(攻殻機動隊をイメージしている)、結果的に頼りになるのはセキュリティ専門家とそれに近いプログラマと手癖が悪いダークウェブ界隈で構成された傭兵部隊だろう。自衛隊も何らかの訓練しているとは思うが、サイバーセキュリティ人材の扱いを見ていると、とても信用できない…
ちょっとプログラミング万能主義的な展開になってしまったが、少なくとも社会のIT技術の受け入れ体制が変わって、かつプログラミング教育が機能したあとの社会を考えると、社会はどう変わっていくか、というのは妄想すると面白いじゃないだろうか、という話。