IPFSについて勉強した
IPFS とは / BitTorrent とどう違うのか
BitTorrentがトラッカーファイルと呼ばれる単位でファイル共有を行うのに対し、IPFS は内部が別のオブジェクトを指し示すポインタ(ディレクトリ相当) or またはバイナリ(ファイル相当)のものがDAG構造をとっていて、それぞれにユニークなキーが振られている。
IPFSの内部構造は Git の内部オブジェクトと非常に似ている。分散ファイルシステムとしての Git との概念的な差はほとんどなくて、両者ともにコンテンツアドレッシング方式の Merkle DAG 構造ということができる。調べた感じ各種ツリーフォーマットの表現の差や、オブジェクトの圧縮方法が違うだけ、といっていってよさそう。
IPFSで配布する際は、URLのような名前空間に対して保存するのではなく、オブジェクトまたはその集合による Merkle によって一意な sha256 のキーが決まり、それが一意性を示すポインタとなる。なのでsha256一致させる高コストな攻撃をされない限り、コンテンツに対してユニークなキーといっていい。
IPFSのP2Pノードとしての振る舞いは BitTorrentに似ており、各ノードがほしいブロックリストと、提供できるブロックリストを公開し、その希少度や見返りのインセンティブによってスコアが付けられる(BitSwapプロトコル)
なので、要約すると Git の分散ファイルシステム + BitTorrent のインセンティブ設計に基づいたファイルブロック交換システムといって良さそう。
P2Pなので、アップロードしたファイルはネットワーク参加者全員の同意を取らないと消せない(=ほぼ消せない)。
libp2p(-js) というミドルウェア層があり、p2pネットワーク内での webrtc/websocket/http を抽象している。IPを利用しているにすぎず、よりメタなプロトコルを採用することも、理論上は可能。
公開してみた
まず、 brew install ipfs などして ipfs コマンドを入れるとする。これで入るのはGoのリファレンス実装で、他にJS実装がそこそこ。CとPythonが In Progress.
こんな感じでアップロードして、ノードに参加し広めることができる
mkdir pub-to-ipfs echo hello > hello.txt ipfs add -r . ipfs daemon # IPFSネットワークの参加ノードとなり、ファイルを配布する
https://ipfs.io/ がデフォルトのゲートウェイで、 https://ipfs.io/ipfs/<ObjectID> という風にアクセスするとその中身が取れる。ipfs daemon は localhost:8080 にローカルのゲートウェイを立ててくれる。
試しに自分のツイッターのアイコンを投げてみた。アクセスできると思う https://ipfs.io/ipfs/QmdqSc9ZKcdzrdfjRmMLms4jH3JtFQCBALyJNTSaEwi59m/saboten.png
{kind=link}
Git をホスティングする
https://kotet.github.io/2018/06/04/ipfs-git-readonly.html が非常に参考になった
手元にあった next-editor のソースを投げてみた。 .git オブジェクトをそのまま投げる。
cd .git ipfs add . -r
Git オブジェクトは 5MB程度なのを確認した。
git clone https://ipfs.io/ipfs/QmQFVzbiueHb6CtuN7aa6W67Uzr9kaeVKsVYLHoFLWDcxz --single-branch
僕の環境で ipfs daemon のノードのPeerが800程度で、Twitter で頼んでこれを clone してもらったところ、およそ1分~6分という結果になった。使い物になるかどうか、微妙なラインでなんとも言えない…。
(アクセス絞るのに --depth 1 しようとしたが、素朴なファイルホスティングだと smart http プロトコルにならず、 dumb http プロトコルだと --depth が使えなかった)
動的なコンテンツを追跡するには ipns というものを使うらしい。まだ使ってないので後で調べる。
わからなかったこと / 次に調べること
やりたかったこととして、 https://next-editor.app は完全な静的サイトで、pure js な Git 実装を積んでて、PWAでオフラインで動くように作っているのだが、 GitHub にアップロードするにはアクセストークンなりCORS迂回のゲートウェイなりの準備が大変。なので、手軽にGitを共有する対象として IPFS へのアップロードする選択肢を用意できるかどうかを検証していた。というか Git って本来分散システムだからGitHubが権威サーバーである必要もないと思っているのだが…。
クライアント単独で git clone し publish までいけたら夢があるし、たぶんいける。検証中。
上記の方法で、サーバーを立ててゲートウェイを通してアップロードできるのはわかった。しかしもっというとブラウザで完全に完結させたくて js-ipfs でIPFSのオブジェクトを作ってブラウザで単独のノードとしてそれを配布したかったが、そのやり方が分からなかった。概念上 WebRTC でP2P への参加ノードになれるはずだが…
共有するためのオブジェクトを作るまではできてて、こんな感じ。
import pify from "pify"; import IPFS from "ipfs"; const streamFiles = (root, files, cb) => { const stream = node.files.addReadableStream(); stream.on("data", data => { console.log(`Added ${data.path} hash: ${data.hash}`); // The last data event will contain the directory hash if (data.path === root) { cb(null, data.hash); } }); files.forEach(file => stream.write(file)); stream.end(); }; const repoPath = "ipfs-" + Math.random(); const node = new IPFS({ repo: repoPath }); global.ipfs = node; // DEBUG node.on("ready", async () => { const root = "xxx"; const files = [ { path: `${root}/file1.txt`, content: node.types.Buffer.from("one", "utf8") }, { path: `${root}/file2.txt`, content: node.types.Buffer.from("two", "utf8") } ]; const directoryHash = await pify(streamFiles)(root, files); const newFiles = await pify(node.ls)(directoryHash); console.log(`${root} - ${directoryHash}`); newFiles.forEach(f => console.log(f.name, f.path, f.hash)); });
もうちょい調べる。
オクトパストラベラー
体験版で感じたとおり、河津ゲーの同人ゲームという印象だった。たぶん今の技術でロマサガ3完全版を作ろうとしたらこんなゲームになるんだろうという感じ。
毒にも薬にもならないシナリオを、やたらウェットなカット演出で見せられる。仲間4人目ぐらいから全部スキップするようになった。会話内容自体はサガシリーズと同じぐらいの(中身がない)情報量なんだけど、声優のフルボイス+ウェイトが挟まる演出で死ぬほどテンポが悪いし、それを全員分見せるためのメタな進行管理が行われていて(飛ばすことはできるが)、とにかくだるかった。
サガのあの無味乾燥な、だけど妙に味のあるテキストは、容量の問題や技術制約もあったんだろうけど、ゲームのテンポを損なわないために必要だったんだな、という学びがあった。
JRPGとしての戦闘システムの出来は悪くないと思っていて、サポジョブでシナジー出して、バフデバフを過不足なく揃えてバーストダメージ出すという現代的な設計で、それは悪くないと思うんだけど、キャラクターやシナリオが全然味気ないのにそれに引っ張られたレベルデザインで、とにかく先が読めてしまう。フィールドのデザインがかなり酷くて、3Dマップの奥行きを使って隠し道に宝箱をおいておく、というパターンしかない。
攻略情報縛ってて、意図的なレベル上げを可能な限り避けてても、かなりぬるく感じた。緊張感出すのに推奨Lv-7ぐらいの進行をしていたが、自分が楽しむには特殊なレギュレーションが必要という感じだった。
スイッチの入れ方
自己分析
どうやったらスイッチが入るか
- コーヒー飲む
- 作業机に着席する
- エディタが開いてある
- 次にやることが自明 => やる
集中継続の仕方
- 取り組んでる対象が面白い
- いい音楽がある
- 通すべきテストがあったり、タスクが明確だったりで、なんらかのリズムがある
- 課題が小さい(小さく分割してあるという状態)
スイッチの切れ方
- コンテキストスイッチのタイミングで開発環境の再セットアップしてると萎えてくる
- 対象がそもそも気が重くて逃げる(タスクが分割されていない)
- Twitter で気になる話題が流れてきて別のスイッチが入ってしまう
- 定期的に腰の調子が気になる
- 定期的に肩の調子が気になる
- 定期的に首の調子が気になる
音楽
- 飽きっぽいので常に新しい音楽がほしい
- 昔はメタルやプログレッシブ・ロックが好きだったが、最近は作業を害さない程度のエレクトロニカに寄ってる
- Spotify はいい感じなのだが、たまに自動再生でやたら癇に障る曲が来て、集中が途切れる
- 思考停止で選ぶ Radiohead / Kid A の一曲目 Everything in its right place の再生数が 1000 回を超えてるがさすがに飽きてる
- https://musicforprogramming.net たまに使う
音楽があると集中してるのは結果的にわかっているが、おそらく集中している結果であって、理由ではない。 しかし因果が逆転しているとしても音楽を流すと自然とコードを書いてることがある。不思議。
戦略
とりあえず何もやる気がでないときは、コンビニでコーヒーを買いにいく。
事前に細かくタスクを分割する。GitHubのイシューを眺める。自分で次にやりそうな内容を思いつき次第メモる。作業中は、作業ディレクトリに TODO.md おいて、CURRENT / ICEBOX に思いつきをひたすら書いてメモしている。こんな感じ https://github.com/mizchi/next-editor/blob/master/TODO.md
t-wada さんには「間があくときは、テストを一件だけわざと落としておくとよい」と言われた。とっかりりになるので。ただそのときはテスト書けるような作業内容ではなかった。要は、最終状態をどう復元するかが大事なんだと思う。最近思うけどTDDやれるテーマってDBとかAPIとかのデータ中心の作業で、UIとかインフラとか副作用がデータの奥にあるものは非常にだるい。タスク管理みたいな別の戦略が必要。
タスクを消化する順番は、モチベーションが上がる順。モチベーションが高まったら気が進まない大ボスに挑む。
数値でゲーミフィケーションされてる作業はモチベが上がりやすい。テストカバレッジとか。イシューの消化数とか、スプリントのポイントとか。ただスプリントのポイントは結局自分で作るのでもやっと感がある。イシューの大きさも
フリーランスでだいたい2〜3社の取引があるので、コンテキストスイッチ対策に、docker-compose で全部立ち上がるという体験が結構大事。開発環境構築ツールとしてのdocker は本当に大事。デプロイ環境はわからん。
あるといいもの
自分でなにか作るとしたらのメモ
- 無理やりやる気をキックするタイマー
- 重くないタスク管理ツール。最近のは全部重い
- エディタに GitHub Issue / Project を組み込む
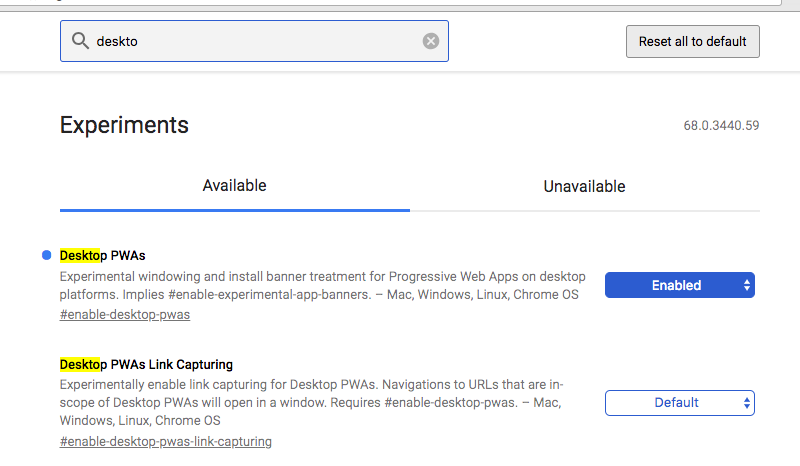
Chrome に PWA for Desktop が来ていたので next-editor で試した
追記: Canary じゃなくてもいいらしいのでタイトル修正した。が…実装具合はよくわからない
今年中に来るとは聞いていたやつ。要はウェブアプリを デスクトップアプリ化する。Electron と違って Chrome の Sandbox と同じ権限で動いている
Twitter Lite をデスクトップ PWA にして使ってるんだけど、最 & 高です。
— Eiji Kitamura / えーじ (@agektmr) 2018年7月12日
Mac だと Chrome Canary で enable-desktop-pwas のフラグを立てると使えます。 pic.twitter.com/0TPhe8gyQL
ちなみに Chrome Canary + フラグは上級者向けなので、自身のない方はいましばらくお待ち下さい。そのうち安定版で普通に使えるようになります。
— Eiji Kitamura / えーじ (@agektmr) 2018年7月12日
試した
Chrome Canary 落として有効化する
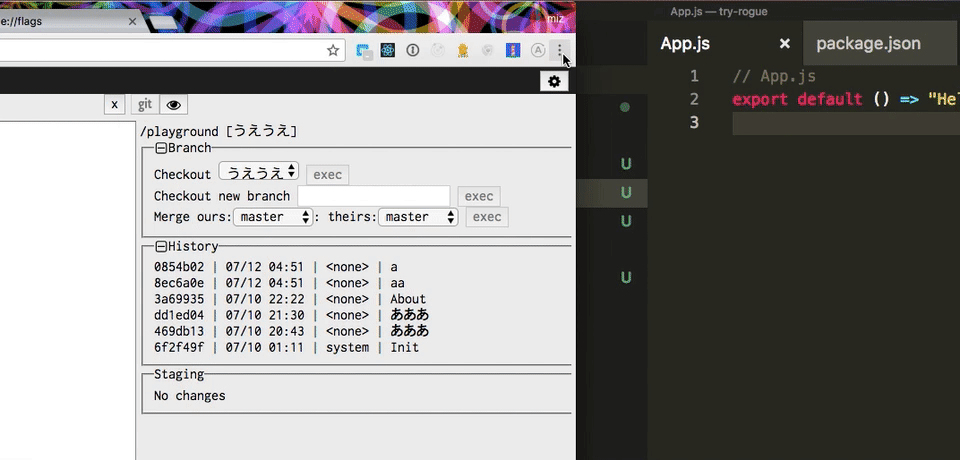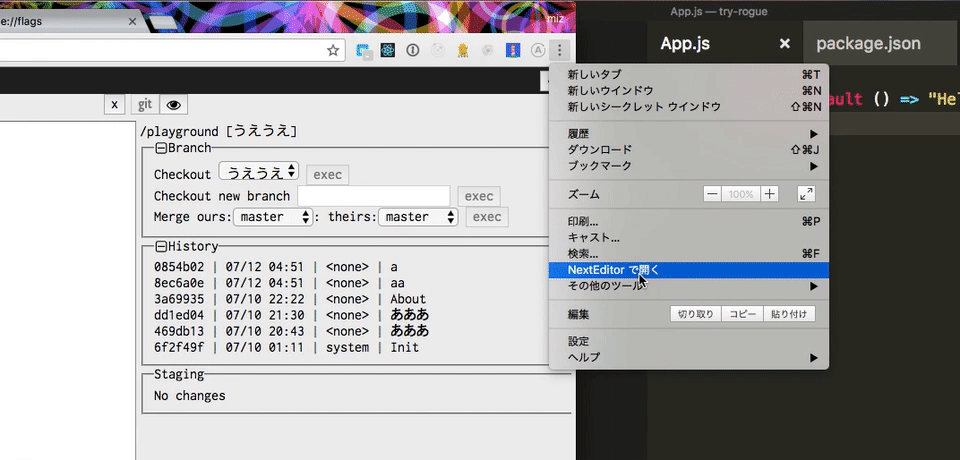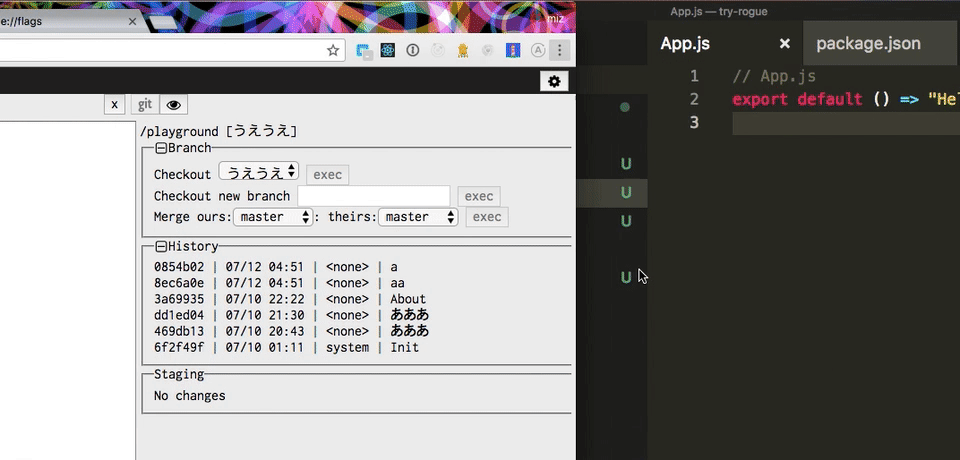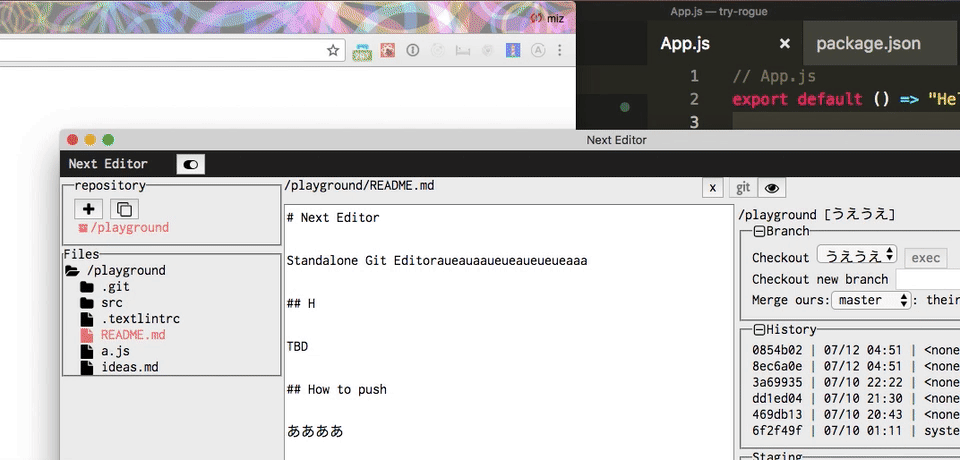
最近作ってる PWA のGit 組み込みエディタの next-editor に試してみた。特に理由がないが PWA 対応していた。オフラインでも Git が動くエディタ。
Next Editor を開いて 「Next Editor で開く」を選択

最高です。
感想
デスクトップPCという世界は業務以外でシュリンクすると思っているのだが、業務やオーサリング系はおそらくいまと同じPCか、それと同じ横長の画面幅のタブレットが長く生き残るだろう。next-editor はそこを狙って作っている。
Electronでアプリを作っていた経験としては、人はそれがどういう実体であろうとも、アプリを起動するメタファとしてのデスクトップアイコンに惹かれるところがある。その点でDock に入るのはすごく嬉しいし、それだけで価値がある。Electronのプロセスモデルの万能性(や、それが引き起こす脆弱性)なんかより、ただ開けるという事実のが大事なんだと思う。
最近まで PCでPWA化するメリットを具体的に説明できていなかったが、とくにツール類はデスクトップ化できるというのが売りになる時代が来ると思っている。
Slay the Spire: 3キャラ目
3キャラ目追加されてたので久しぶりにやった。 たぶん4回目ぐらいの挑戦でクリア。
Pyramid + Cursed Key と引けたので理想的な展開。最終的なビルドどんな感じになったかはこの動画の通り
だいぶ前に紹介記事を書いたけど、売れてるみたいでよかった。
デッキ構築型ローグライクRPG『Slay the Spire』100万プレイヤー突破。わかりやすく奥深いゲーム性が人気を呼び、Steamの定番タイトルに | AUTOMATON
漸進的型付け言語の時代に必要なもの
最近では、Gradual Typing、漸進的型付けと呼ばれる型システムを備えた言語(拡張)が増えてきています。
次のようなもの
- JavaScript: TypeScript / Flowtype
- Python: mypy / pyre-checker
- PHP: hack / php-storm
flow/pyre-checker/hack と facebook 製が多いですね。
この記事は、それらを使う動機と運用について書きます。この記事の出発点として、 おそらく TypeScript/Flow で発生した問題が後発の言語で発生すると思っており、それらを使う方や、設計する人への提言でもあります。
自分は昔 https://github.com/mizchi/TypedCoffeeScript というAltJS作ろうとして、実装のツラミはなんとなく知ってるつもりです。ホビーレベルで作るものではなかった…。
型アノテーションの再評価
一昔前の Web プログラミング言語のトレンドは動的型付け一辺倒でしたが、その時代も終わり、静的な型宣言を再評価するフェーズが来ているように思います。
この背景には、おそらく Web プログラミングの規模が年々肥大化しており、動的検査のコストが増してきたのが理由にあるでしょう。
WAFの考え方だと、型をつけづらい外部IOであるところのHTTPリクエストを受け、HTML文字列を返す、という世界観では、型宣言は単に「おまじない」を多くするだけの邪魔者だったかもしれません。外部IOに型をつけづらいのは、外部IOの本質的な問題ではあります。
しかし今では、どのWAFも内部では分厚いビジネスロジックを持ち、実質的に静的なフィールドを持つORMを読み書きし、何らかの型を暗に想定する JSON を返す、という風にトレンドが変わってきました。型やIDEの支援なしにコードを育て続けるには、逆に高度なモジュール分割のノウハウや、状況に応じたストラテジーが必要になっています。
それらの肥大化の対応として、ドキュメントを書く文化や、テスト駆動も普及してきましたが、一周回って「検査可能なドキュメント」としての型アノテーションの価値が再評価されたように思います。
誰のための型か
注意してほしいのは、ここでいう型宣言の需要は、人間のために書く、ドキュメントとしての型アノテーションで、コンパイラに効率よくランタイムを生成してもうらための型ではありません。これを混同している人が多いですし、「高水準な、良く設計されたプログラミング言語」はそれらを区別せずにプログラマに書かせようとしてきます。(Rust などは低水準を目指しているので明示的に区別します)
言語としてその方針は間違ってないですが、使う側や、言語を選定する側は区別しないといけません。抽象メモリマシンである C や、型の表現が未発達だった時代の Java の冗長な宣言などに引っ張られて静的型付けを批判する人がいますが、それらは現代の静的型付け言語ではないです。最近の推論機は優秀で、見た目上は動的型付けと同じものを書けます。
また Language Server Protocol といったエディタのためのプロトコルによって、静的解析できるメタデータの重要性も上がっています。
何の機能をもってどう表現するかは、 私と型システムとポエム - The curse of λ という記事で、よく雰囲気が表現されています。
漸進的型付けの登場
What is Gradual Typing: 漸進的型付けとは何か - Qiita
基本的に、動的型付の言語に後付で型宣言を追加するものです。このとき、これらが新しい言語やコンパイラと言うのはちょっと微妙なところで、例えば TypeScript + Flow は拡張文法のパーサ + 拡張文法を取り除くだけのコンパイラ + 静的検査という組み合わせで、どちらというと Linter などに立ち位置が近いです。
自分が知る限り(主に TypeScript, Flow, Dart)、こういう特徴があります。
- 未知の変数は any 型であると仮定する
- あらゆる変数の型は any 型にアップキャストできる(Top)
- any 型はあらゆる型にダウンキャストできる(Bottom)
- あらゆる型は any 型と合わせて操作すると any にアップキャストされる
- 自分で宣言した型を扱う限り、型エラーが発生する
- 型アノテーションはランタイムに関与しない
(typescript の scrictAny や noImplicitAny オプションはこの挙動をより厳密にコントロールできます)
つまり、こういうコードが通ってしまいます。
const x: number = 1 const y: any = x const z: string = x + y // pass
これが駄目だという話ではなく、型システムを後付している以上、柔軟性の方が重視されます。というかそうでないと、コンパイラを納得させられずに開発が「詰む」ことがあります。 any を書いた際に守るかどうかは自己責任です。
「型アノテーションはランタイムに関与しない」が特徴的で、型アノテーションを取り除くコンパイラとともに実装されるのも合わせて、なんというかそれ自身では控えめなコンパイラです。その結果として現れる挙動として、Flow/TypeScript は int や float の宣言はできず、必ず number として扱う必要があります。
また、既存のものに無理矢理型を当てはめるという特性上、Generics、Union Type, Subtyping といった高度な型表現を備えているのが事実上必須な特性となっています。
type X<T> = T | null | [T, T] | Array<T | 1> | 'yeah!' | 1 | 2
こんな風になったりしますね。
元は動的型付けからの発展だと思うと、この柔軟さや、any への妥協は必要なラインだと思います。
漸進型付けの利点
- 既存の資産をそのまま利用できる
- 「自分で書く範囲のコードは」厳密に運用することができる
一応言っておきますが、僕は動的型付の言語をすべて否定しているわけではなく、大規模なコードに適用するのはそぐわないという意見です。
一つのことをうまくやるUNIX哲学に照らし合わせても、文字が来て文字を返すぐらいに抽象化されたエコシステムでは、型宣言はそこまで重要視されないでしょう。たとえば npm のほとんどそういう世界だと思っています。
その上で、動的型付けのノウハウと資産を活かしつつ、その利用者になりつつ、巨大なアプリケーションを構築する手段として漸進型付けは有用だと思っています。
漸進型付けで発生した問題
ここからは自分が TypeScript と Flow の運用で発生した問題について。
TypeScript/Flow では、npm の資産をそのまま動かせる、というかランタイムに全く関与しないのですが、基本的に、扱うライブラリの型宣言はないです。
https://github.com/DefinitelyTyped/DefinitelyTyped や https://github.com/flowtype/flow-typed/ という型定義の集積リポジトリがあります。ただしこれらが使い物になるかというと、おおよそ使えつつも様々な問題が起きます。
- そもそも型が付けられるインターフェースではない(redux.combineReducers など)
- 作者が型定義の運用に興味がない(PRを受け付けてくれない)
- ↑の問題の結果、作者以外によって書かれた型アノテーションが間違っている
- Generics がある以上、型定義が一意に定まらず、定義者の主張が強く出てしまう
そもそも型が付けられるインターフェースではない(redux.cobineReducers など)
たとえば、Redux の combineReducers は (State, Action) => State の reducer と呼ばれる関数を複数合成して、新しい (State', Action') => State' の新しい関数を生成する関数です。
combineReducers({
counter, user, auth
})
これで、合成される State' は次のような型になります。
{
counter: {...},
user: {...},
auth: {...}
}
これらをTypeScript/Flowの推論器で一般化するのはちょっと難しく、flow では専用の $compose という型で実装されようとしていますが、いまいち使いづらいので、結局推論器に任せずに自分でその型を宣言しなおすことになります。
これにかぎらず、JS の昔ながらのイディオムだと options: boolean | { isXXX: boolean, ... } みたいな引数が多く、型を付けられなくはないが、ダイナミックすぎて、ユニオンタイプを酷使するみたいな状況が起こりがちです。
作者が興味がない | 作者以外が書いた型が間違っている | 型の解釈の意見が合わない
そもそも言語拡張なので誰もが使うというものではなく、立場が弱いです。作者が興味が無いから PR が無視されたり、メンテ出来ないからごめんね、といってリジェクトされます。
また、Generics によって型の一意性はないです。
type Foo = { a: number, b: string }
という型があったとして、その定義は
type A<T> = { a: number, b: T }
type Foo = A<string>
なのか
type B<T> = { a: T, b: string }
type Foo = B<number>
なのか、使う人によって解釈が異なります。作者以外が書いてる場合は尚更です。ユーザーが使いたい時の値が Foo だとして、ライブラリとして提供される型の表現が A なのか B なのか、解釈に依存します。またどれぐらいの厳密なのかも方針次第で異なって、単に any で型名がわかるだけだったり、逆にオプショナルな値が解釈違いで必須になっていたりといった手続きが頻出します。
また、厳密な型定義ができるように Generics を大量に使ってしまった結果、高難易度な型パズルが頻出するライブラリが疎まれたりします。DefinitelyTyped/index.d.ts at master · DefinitelyTyped/DefinitelyTyped · GitHub
気に食わないなら自分で書き治すか、諦めて any にキャストする必要があります。
実際の運用について
興味がないのものを握りつぶす
実際に型がないと困るのは自分の扱うコードと接する範囲です。これらを厳密に扱う必要がないときは、単に無視します。 これに型を書いてもいいですが、現実に扱うすべてのコードに型をつけるのは現実的ではありません。よほど暇な時でしょう。
// declaration.d.ts declare module "a"; declare module "b";
// flow-typed/lib.js.flow
declare module "a" { };
declare module "b" { };
握りつぶした上で、段階的に自分が興味がある範囲の型を徐々に追記していく、ということが多いです。
外部IOの出口を押さえる
とにかく大事なことは、自分が扱う範囲の型を守ることです。
function parseXXX(input: {args: string[]}): {data: string} {
// input から文字列を取り出して加工する
return { data }
}
const {data} = parseXXX(input as any)
input にはもっといろんなプロパティがありますが、ここでは args にしか興味がないとして、 最終的に data: string が帰ればOK、というやつです。
これは 最終的に string にダウンキャストして扱っています。ここは型がない危険な領域ですが、まあ頑張るとする。
express のようなサーバーを扱ってると、うまく型がつかず、こういう風にラップしていることが多いです。
後発の言語へ言いたいこと
Python 3.5 や、もしかすると Ruby 3 にも型が入るかもしれません。
TypeScript/Flow はそれ自身の立場が弱いので、ライブラリへの型定義ファイルのPRが受け入れられず、外部の型集積は結構な地獄になってしまいましたが、静的型付けを受け入れられない作者がおそらく一定数いる以上、どの環境でもないよりはマシです。
ただし、それらは握りつぶせる必要があります。原則的に型宣言や型推論ありきで運用するのは、別の言語として再スタートしない限りは不可能です。
また、既存のコードが型を想定していない以上、推論器の限界で表現できないものがたくさんあります。また、逆説的ですが、表現力がありすぎる型とその型推論は、使う側も結構辛いです。
たとえば、 flow の Redux connect の型定義はこうなっています
declare export function connect<Com: ComponentType<*>,
A,
S: Object,
DP: Object,
SP: Object,
RSP: Object,
RDP: Object,
MDP: Object,
MP: Object,
RMP: Object,
ST: $Subtype<{[_: $Keys<Com>]: any}>
>(
mapStateToProps: ?MapStateToProps<S, SP, RSP>,
mapDispatchToProps: ?MapDispatchToProps<A, DP, RDP>,
mergeProps: MDP,
options: ConnectOptions<S, SP & DP & MP, RSP, RMP>
): (component: Com) => ComponentType<$Diff<ElementConfig<Com>, RMP> & SP & DP & MP> & $Shape<ST>;
パッと見、よくわかりません。推論機の癖を読み切ってジェネリクスを一つずつ解いて型パズルを完成させる必要があります。単に無視されてアップキャストされることのほうが多いです。そして割れ窓になります。
matz は Ruby に型宣言を入れずに推論機でどうにかしたいと言っていましたが、おそらく後方互換性を保ったままだと不可能だと思います。それはそれとしてドキュメントとしての型宣言は選択肢として提供するべきではないでしょうか。
Flow や mypy みてると思ったのは、むしろ言語として実装するのは型アノテーションのフィールドの構文予約だけでよくて、その実装はコミュニティに丸投げでいいのかもしれません。
最後に
ネガティブな点を多々挙げましたが、これらは 0 を 1 にする際の、型宣言がなかったものをあるようにするための一歩のための苦しみで、これ自体は間違いなく進歩だと思います。
最初から型がある言語でやればいいのでは?というツッコミはもっともなんですが、サーバーサイド以外はプラットフォームによって言語を選べないことが多く、JavaScriptはその最たるもので、ある種苦肉の策であります。
個人的には単一の推論ルールを持った処理系を、環境によってその厳しさを調整できると嬉しいような気がしていますが、そういう柔軟性がある言語はいまのところ無いですね。
新技術の紹介する際の「魂が震える」テキストのパターン
これは自己観察の結果で、自分が新しい技術の採用を行う際にアジる記事のパターン、個人的に「魂が震えるシリーズ」と呼んでるんですが、それがどういう文章構造を持つことが多いかメタ的に解釈したものです。
単に誰もがこうすればいいという話ではないではないです。功罪あると思ってます。
導入
- 新技術の既存の文脈での解釈
- +αの示唆
- 仮想敵の宣言
概要
- 説明
- ポテンシャルの例示
- 極端な例の例示
- 現実的な制約の存在で現実に引き戻す
- ユーザーが知るべきことを要約
実例
- 既存の技術とのアナロジー
- 古い手法から進化している点を指摘
- 今の手法の問題点をいかに解決してどんな未来が来るか
応用
- 既存の考え方を、あたらしい技術で再解釈
- 本来は無関係だった他の技術との親和性を指摘
課題
- 新しい技術ゆえのエコシステムのなさを指摘
- 構造上の欠陥を指摘
- まず取り掛かれる現実的なエントリポイントを例示
未来
- ここまで読んできたなら良い面悪い面わかってるはずだ、といって再読を促す
- 俺はこの技術にベットすると宣言し、お前はどうだ、と煽る