「この〜を導入すると、なんとこうなりました!どうです?わかりやすいと思えませんか?」
主にUI設計やプログラミングのAPI設計について、「わかりやすい」というのは主観的で合意が取れないのでクソという話。
- 定量的な指標が示されてない
- そもそも趣味が合わない場合はそこで終わり
- 〜の本来意図された機能が隠れてしまっている
- ↑によって隠れてしまった機能を呼び出すのが、最終的にコストが掛かる
何が言いたいかと言うと、「指標の伴わない変更に意味はない」「APIの呼び方を変える程度のラッパーライブラリやヘルパーには、特に意味がない」ということです。
ここからプログラミングの話に絞りますが、特にショートハンドしたいだけの場合、ショートハンドするAPIの実装は、必ず本来の機能を呼び出す脱出ハッチも必要となります。
よく練られていない「わかりやすさ」は、次第にこの脱出ハッチを使うことを要求するようになり、結果として捨てられることになります。この破棄までの過程は、結果的に「技術的負債」と表現されるわけです。
例外は、あります。裏にある仕組み、概念、データ構造やアルゴリズムがとても秀逸で、しかしそのAPIの提供者が、ユーザーに見せるセンスが壊滅的な場合。
しかし、大抵の場合は、よく使われているライブラリのAPI作者は、よく練った上でそれを提供しているわけで、そう思えたとしても、ユーザーの無理解に起因していることが大半です。ラッパー関数を提供して、最終的にそれを使用しなくなる、というのは、プログラマなら誰でも経験したことがあるでしょう。
というわけで、ユーザーを混乱させるようなヘルパやライブラリを「作らない」ことにも価値があるのではないでしょうか。
もちろん、作ってみる経験は大事だと思いますけど、採用には必ず誰かを巻き込んだ議論が必要で、主観的な指標によらない、複数人による議論を経るという過程にこそ価値があるわけです。最終的には、とある実装ではなく、単に慣習やベストプラクティスという形に落ち着くかもしれません。例えばそういうものとして広まったものに、JSON などがあります。
というわけで、「わかりやすさ」の主張には慎重になってほしい、という話でした。
JavaScript エンジニア向け: 知識ゼロから tensorflow.js で機械学習入門
この週末で機械学習を勉強した結果として、JavaScript エンジニア向けにまとめてみる。
自分が数式見て何もわからん…となったので、できるだけ動いてるコードで説明する。動いてるコードみてから数式見たら、多少気持ちがわかる感じになった。
最初に断っておくが、特にJSを使いたい理由がないなら python で keras 使ったほうがいいと思う。tensorflow.js が生きる部分もあるが、学習段階ではそこまで関係ないため。
追記: 最初 0 < a < 1.0 0 < b < 1.0 で三角関数 Math.sin をとっていて、これだと三角関数の一部の値しか使っておらず、線形に近似できそうな値を吐いていたので、次のように変更して、データも更新した。
// 修正前 const fn = (a, b) => { const n = Math.cos(a) * b + Math.sin(b) * a; return a > b ? n : -n; }; // 修正版 const fn = (a, b) => { const n = Math.cos(a * Math.PI * 2) * b + Math.sin(b * Math.PI * 2) * a; return a > b ? n : -n; };
これにより、精度はやや落ちた。
概要
やりたいこと: ある関数の、入力と出力を模倣したい。
ニューラルネットを使うとどうなるか。
- モデルのネットワークは何かしらの関数を近似する
- 入力と出力は何かしらの行列(tensor)で表現される
ニューラルネットワークでは、ある入力のときの出力を見て、モデルに期待する値との誤差を教えると、ネットワークがその値を生成するように変化する
例
真のモデル関数 f = (a, b) => a + b が あったとき、モデルにはこの中身を教えず、その振る舞いを覚えさせたい。
入力値 [1, 3] を与えた際、 model.predict([[1, 3]]) が [[0]] を生成したとする。このときの期待する値 4 との差 -4 が model に伝えられると、4 を生成しやすいように、内部のネットワークの重み(weight, bias)が変化する。
ニューラルネットの中身がどうなってるか、とりあえず一番最初はブラックボックスだと思ってよい。なんかいい感じにやってくれる。
実際どう定義されているか、誤差からどうその重みが変化するかは、バックプロパゲーションなどで検索。
考え方
つまり、何かしらの状態を行列の表現に落として、その結果をどう評価するか既にわかっていて、また入力値が適切な因子として出力に関与することができ、また十分にモデルの内部ネットワークの複雑度があれば、大量のデータを与えると値が収束していく。
なので、何も仮説無くデータを突っ込んでも、適切なデータは出ないかもしれない。適切な因果を持つ、入力と出力のペアがあれば、データを与えれば与えるほど、精度が高くなる。
tensorflow.js で関数の振る舞いを予測する
ここから実践編。
適当に、こういう関数をでっち上げた。何も参考にしていない。完全にこの場の思いつきである。
const fn = (a, b) => { const n = Math.cos(a * Math.PI * 2) * b + Math.sin(b * Math.PI * 2) * a; return a > b ? n : -n; };
この関数は、与えられた a, b に対して結構複雑な振る舞いをする。正直自分でも頭の中でグラフ掛けないし、予測がつかない。三角関数を使ってるのと、a > b の比較を行っているので、非線形(直線ではない)振る舞いをする。
このとき、(a, b) の出力は無限にこの関数で生成できるので、それを教師データとして使って、誤差を伝えるように訓練する。
以下、そのときの tensorflow.js を使ったコード。30000 回実行してみた。
import "@babel/polyfill"; import * as tf from "@tensorflow/tfjs"; import "@tensorflow/tfjs-node-gpu"; // Intel Cuda の対応OSのみ有効 const fn = (a, b) => { const n = Math.cos(a * Math.PI * 2) * b + Math.sin(b * Math.PI * 2) * a; return a > b ? n : -n; }; function buildModel() { const model = tf.sequential(); model.add( tf.layers.dense({ units: 20, activation: "relu", inputShape: [2] }) ); model.add( tf.layers.dense({ units: 20, activation: "relu", inputShape: [1] }) ); model.add( tf.layers.dense({ units: 20, activation: "relu" }) ); model.add( tf.layers.dense({ units: 1, activation: "linear" }) ); model.compile({ optimizer: "sgd", loss: "meanSquaredError" }); return model; } function train(model, count = 30000) { // create data const inputs: number[][] = new Array(count) .fill(0) .map(_ => [Math.random(), Math.random()]); const answers: number[][] = inputs.map(x => [fn(x[0], x[1])]); const xs = tf.tensor2d(inputs); const ys = tf.tensor2d(answers); return model.fit(xs, ys, { epochs: 100, callbacks: { onEpochEnd: async (epoch: any, log: any) => { console.log(`Epoch ${epoch}: loss = ${log.loss}`); } } }); } async function run() { const model = buildModel(); await train(model); console.log("--- use trained model"); new Array(10).fill(0).forEach(() => { const input = [Math.random(), Math.random()]; const pred: any = model.predict(tf.tensor2d([input])); const real = fn(input[0], input[1]); console.log("in", input, "pred", pred.dataSync()[0], "real", real); }); } run();
なんか dense だの relu だの sgd だの meanSquaredError だの epoch だのいろんな概念が出てくるが、一旦はおまじないとして、気になったらググる感じで。実際には大したことない、身構えたのが馬鹿らしくなるような、シンプルな定義が多かった。
30000 回実行した後、本当に訓練できたか確認するのに、10 回実行してみている。
その結果
... eta=0.0 ================================> loss=0.01 2367ms 79us/step - loss=0.01 Epoch 97: loss = 0.008017721727490426 Epoch 99 / 100 eta=0.0 ================================> loss=0.01 2408ms 80us/step - loss=0.01 Epoch 98: loss = 0.007897231815196575 Epoch 100 / 100 eta=0.0 ================================> loss=0.00 2309ms 77us/step - loss=0.01 Epoch 99: loss = 0.008164751819210747 --- use trained model in [ 0.3962178765532509, 0.7682131016008036 ] pred 1.0202405452728271 real 1.0042189244656015 in [ 0.5636312166233701, 0.3811451901186962 ] pred 0.015699267387390137 real 0.031779120347658674 in [ 0.29081139359722297, 0.6065326337942547 ] pred 0.35762453079223633 real 0.3342764533539708 in [ 0.7485062557383053, 0.9206256550585616 ] pred 0.2782783508300781 real 0.3666547430935932 in [ 0.5138481068330991, 0.04557842574637938 ] pred 0.1076730489730835 real 0.09974545365571702 in [ 0.9162600474832179, 0.837541216933819 ] pred -0.043701171875 real -0.056856406373799406 in [ 0.7299011854033057, 0.8539316678532747 ] pred 0.5823078751564026 real 0.6872769887438305 in [ 0.02929035990521056, 0.4067624521196973 ] pred -0.445804238319397 real -0.4160877981686353 in [ 0.7649246937480239, 0.9202537029736069 ] pred 0.1884562373161316 real 0.28126628339301984 in [ 0.21538151181392773, 0.8708798400126363 ] pred -0.08348429203033447real -0.03174978980219534
思っていたより高い精度が出た。
正直、自分の思いつきの関数がここまで高い精度で模倣されたことにビビっている。とくに a > b の正負の出力に関してはほぼ確実に当ててきている。
最初は a + b や Math.sin(a + b) でやってみて、すぐ収束したのでこれなら無理じゃないかって関数を突っ込んでみてこの精度なので、結構感動していた。訓練時間は手元で 3 分ぐらい。
ちなみに、 tensorflow.js はブラウザ環境では WebGPU を使って訓練するので、下手な CPU 環境より速い。
追記: 200000回
26分掛けて200000回やってみた。誤差 0.008 から 0.003程度まで精度が上がった
eta=0.0 ================================> loss=0.00 15717ms 79us/step - loss=0.00 Epoch 96: loss = 0.002879959831906017 Epoch 98 / 100 eta=0.0 ================================> loss=0.00 15722ms 79us/step - loss=0.00 Epoch 97: loss = 0.003037940525643062 Epoch 99 / 100 eta=0.0 ================================> loss=0.00 15697ms 78us/step - loss=0.00 Epoch 98: loss = 0.0030612829002237413 Epoch 100 / 100 eta=0.0 ================================> loss=0.00 15749ms 79us/step - loss=0.00 Epoch 99: loss = 0.0031942650708649306 --- use trained model in [ 0.894890579256173, 0.791992136427107 ] pred -0.24931591749191284 real -0.23845978737014883 in [ 0.33861845138126845, 0.14223981949273057 ] pred 0.19588708877563477real 0.18875113058190596 in [ 0.533338516856545, 0.0756469011023253 ] pred 0.1673297882080078 real 0.17006682242955357 in [ 0.8359911024259461, 0.577326973633683 ] pred -0.09570872783660889 real -0.093409575348611 in [ 0.05713099891468687, 0.27499415441712993 ] pred -0.2965472340583801real -0.31389426496282413 in [ 0.2842413125538461, 0.19573535679085463 ] pred 0.2440524697303772 real 0.22609192489185875 in [ 0.8549135971844535, 0.7277203717553344 ] pred -0.4215628504753113 real -0.40083794824237673 in [ 0.8235456930613112, 0.2048808799839672 ] pred 0.8972318172454834 real 0.8820155692003951 in [ 0.8671403644770563, 0.47572531583815847 ] pred 0.4355853497982025 real 0.45111927209825686 in [ 0.853777499934028, 0.09838342580279558 ] pred 0.5768846273422241 real 0.5544972469695729 ✨ Done in 1592.47s.
応用
tensorflow 自体は、入力と出力の最適化をしてくれるだけで、実際にどういうモデルを構築するか、どういう入力を与えるかは、結局人間が考える。
モデルをどう作るかは、最初は検討もつかないかもしれないが、自分もよくわからなくていろんな人に聞いたが、結局うまくいったモデルを参考にするしかないとのこと。大抵は論文になっていて、その解説があって、そのネットワークの構造をコードに落とすと再現できる(らしい。自分もまだそこまでたどり着いてない)。
流行りのものだと、画像を入力にする時にいい感じに次元を絞るのが CNN、時系列データから最終的な結果を全体に伝搬させたいのが DQN、2 つのモデルを競わせたり検証させたりするのが GAN、という理解をしている(GAN はまだふわっとしている。これから実装して勉強する)
勉強するなら
今回は js で書いたが、正直 python の方が keras での実装例が多くて勉強は捗ると思う。jupyter やら matplotlib だの色々便利ツールがある。
自分が tensorflow.js で遊んでるのは、ブラウザゲームのゲーム AI を作りたくて、js と python で同じ環境を二回実装するのが嫌、という理由なので、そういう理由がなければ python で keras 使っとくのがいいと思う。
python で実行した tensorflow のモデルを、tensorflow.js でも使えるような json にコンパイルできるので、訓練環境はどっちでもいい。
というのが一週間ぐらい勉強した成果。
keras 使って DQN で迷路を解いてみた
世界観をつかめるぐらいには機械学習やっておきたいと思い、とりあえず何かしらのお題がないと興味が続かなさそうなので、二次元の盤面上で何かしらの行動をする、ローグライクのモンスターのエージェントを作るのを目標にしようと思う。自分がゲーム作るとき、大抵エージェントのルール作る段階で飽きてくるので。
今回の記事は、迷路を解くところまで。
学習資料
- [Python]強化学習(DQN)を実装しながらKerasに慣れる - Qiita
- DQNをKerasとTensorFlowとOpenAI Gymで実装する
- 全力で人工知能に対決を挑んでみた(理論編) - ニコニコ動画
雰囲気を掴むのに、ニコ動の解説動画わかりやすかった。
よく使われてる OpenAI Gym 、見た目は派手だが、環境変数が多すぎていまいち理解の助けにならない + 次元が多すぎて収束が遠いので、すごい単純なゲームルールを自分で作って、それを自分で解く形式を探した。
その結果、迷路を解かせるこのコードがわかりやすかったので、これをリファクタしながら勉強した。
https://github.com/shibuiwilliam/maze_solver
こっちは自分のリファクタ後のコード。迷路生成部分を含めて268行。Solver の定義 + 訓練は 150行ぐらい。
keras tensorflow numpy が入ってれば動くはず。元コードは pandas 使ってたが、リファクタしてたら不要になった。
勉強過程で、コピペでポンと動くやつがなかなかなくて困ったので、シングルファイルでポンと動くことを意識してる。環境構築は 前回の記事参照。
ゲームルール
- 10x10のランダム生成の迷路を S から G までゴールできれば50点
- 踏むと -1点 されるマスが散らばってる
- 一番高いスコアでゴールできたモデルの勝ち
こんな感じ(@@ はエージェントの位置)
.
# # # S # # # # # #
# -1 # 0 -1 # 0 0 -1 #
# -1 # -1 0 0 -1 -1 -1 #
# 0 -1 # # 0 -1 -1 -1 #
# 0 0 0 0 0 0 # 0 #
# 0 -1 -1 0 0 -1 -1 # #
# -1 -1 0 0 # -1 -1 0 #
# -1 # -1 0 -1 -1 -1 -1 #
# 0 0 0 -1 -1 @@ -1 -1 #
# # # # # # 50 # # #
環境はいわゆるゲームって感じの実装で、機械学習は全然関係ない。
DQN Solver の考え方
点p(x1, y1) から 点p(x2, y2) へ遷移する際のスコアを表にする(マルコフ決定過程)
[p(0, 1) => p(0, 2)] => score(p(0, 1), p(0, 2)) [p(0, 1) => p(1, 1)] => score(p(0, 1), p(1, 1)) [p(1, 1) => p(1, 2)] => score(p(1, 1), p(1, 2)) ...
score の評価関数は、そのときのスコアと、さらにその次で取りうる一歩の中うち、最大のスコアになるものにγを掛けたものを足す。(今回は0.9)
その部分のコード (target_f がそれ)
if done: target_f = reward else: next_rewards = [] for a in next_movables: np_next_s_a = np.array([[next_state, a]]) next_rewards.append(self.model.predict(np_next_s_a)) np_n_r_max = np.amax(np.array(next_rewards)) target_f = reward + GAMMA * np_n_r_max
次の一歩を先読みしてるスコアになっているので、何度も繰り返すうちに、最終的にプラスになるものが各セルの評価スコアとして伝搬されるはず。次の一歩の評価を含んでいるので、中間状態でマイナスになっていてもそれも打ち消される。
学習ステップ
- とりあえず最初はゴールするまでランダムに歩かせる
- 行動履歴の中から、ランダムで(最大)32個の状態を取り出して、
p(x1, y1) => p(x2, y2) => rewardのスコアの組を model.fit (訓練) する - ε-greedy で訓練された予測スコアに少しずつ従うようになる
訓練部分
def replay_experience(self, batch_size): batch_size = min(batch_size, len(self.memory)) minibatch = random.sample(self.memory, batch_size) x = [] y = [] for i in range(batch_size): state, action, reward, next_state, next_movables, done = minibatch[ i] input_action = [state, action] if done: target_f = reward else: next_rewards = [] for a in next_movables: np_next_s_a = np.array([[next_state, a]]) next_rewards.append(self.model.predict(np_next_s_a)) np_n_r_max = np.amax(np.array(next_rewards)) target_f = reward + GAMMA * np_n_r_max x.append(input_action) y.append(target_f) self.model.fit(np.array(x), np.array([y]).T, epochs=1, verbose=0)
行動選択部分
def choose_action(self, at, movables): if self.epsilon >= random.random(): return random.choice(movables) else: return self.choose_best_action(at, movables) def choose_best_action(self, at, movables): best_actions = [] max_act_value = -100 for a in movables: np_action = np.array([[at, a]]) act_value = self.model.predict(np_action) if act_value > max_act_value: best_actions = [ a, ] max_act_value = act_value elif act_value == max_act_value: best_actions.append(a) return random.choice(best_actions)
訓練されるモデルの定義
def build_maze_solver(): model = Sequential() model.add(Dense(128, input_shape=(2, 2), activation='tanh')) model.add(Flatten()) model.add(Dense(128, activation='tanh')) model.add(Dense(128, activation='tanh')) model.add(Dense(1, activation='linear')) model.compile(loss="mse", optimizer=RMSprop(lr=LEARNING_RATE)) return model
最初の層の input_shape が (2, 2) なのは (x1, y1), (x2, y2) のような形になるため。最後の activation する層が、予測される reward の出力。中間層は二層。なんで二層かはよくわかってない。たしかにこれで収束する。
10000回ゴールするまで実行する。(たぶん、収束するまで10000回じゃ足りないのだが、何度もデバッグするのが面倒だったので減らしている)
EPISODE_COUNT = 10000 MAX_WALK_COUNT = 1000 solver = Solver() for e in range(EPISODE_COUNT): at = field.start_point score = 0 for time in range(MAX_WALK_COUNT): movables = field.get_actions(at) action = solver.choose_action(at, movables) reward, done = field.get_value(action) score = score + reward next_state = action next_movables = field.get_actions(next_state) solver.remember_memory(at, action, reward, next_state, next_movables, done) if done or time == (MAX_WALK_COUNT - 1): if e % 500 == 0: print("episode: {}/{}, score: {}, e: {:.2} \t @ {}".format( e, EPISODE_COUNT, score, solver.epsilon, time)) break at = next_state solver.replay_experience(32)
結果
episode: 500/10000, score: -486.0, e: 0.95 @ 999 episode: 1000/10000, score: -9.0, e: 0.9 @ 126 episode: 1500/10000, score: 20.0, e: 0.86 @ 40 episode: 2000/10000, score: -108.0, e: 0.82 @ 280 episode: 2500/10000, score: 17.0, e: 0.78 @ 54 episode: 3000/10000, score: 25.0, e: 0.74 @ 46 episode: 3500/10000, score: 23.0, e: 0.7 @ 34 episode: 4000/10000, score: 20.0, e: 0.67 @ 50 episode: 4500/10000, score: 31.0, e: 0.64 @ 26 episode: 5000/10000, score: 10.0, e: 0.61 @ 56 episode: 5500/10000, score: 23.0, e: 0.58 @ 48 episode: 6000/10000, score: 35.0, e: 0.55 @ 20 episode: 6500/10000, score: 31.0, e: 0.52 @ 32 episode: 7000/10000, score: 41.0, e: 0.5 @ 16 episode: 7500/10000, score: 38.0, e: 0.47 @ 24 episode: 8000/10000, score: 36.0, e: 0.45 @ 24 episode: 8500/10000, score: 38.0, e: 0.43 @ 24 episode: 9000/10000, score: 37.0, e: 0.41 @ 30 episode: 9500/10000, score: 38.0, e: 0.39 @ 22
score が徐々に上がって、辿り着くまでのステップ数も減っていってる
中間層の数でどのような影響があるか
全部抜いてみた
def build_maze_solver(): model = Sequential() model.add(Dense(128, input_shape=(2, 2), activation='tanh')) model.add(Flatten()) model.add(Dense(1, activation='linear')) model.compile(loss="mse", optimizer=RMSprop(lr=LEARNING_RATE)) return model
結果
episode: 500/10000, score: 7.0, e: 0.95 @ 75 episode: 1000/10000, score: -51.0, e: 0.9 @ 257 episode: 1500/10000, score: -59.0, e: 0.86 @ 349 episode: 2000/10000, score: -343.0, e: 0.82 @ 999 episode: 2500/10000, score: -262.0, e: 0.78 @ 999 episode: 3000/10000, score: -277.0, e: 0.74 @ 999 ...
初回は偶然うまくいったが、全く収束しなくて笑った
一つだけ抜いてみた
def build_maze_solver(): model = Sequential() model.add(Dense(128, input_shape=(2, 2), activation='tanh')) model.add(Flatten()) model.add(Dense(128, activation='tanh')) model.add(Dense(1, activation='linear')) model.compile(loss="mse", optimizer=RMSprop(lr=LEARNING_RATE)) return model
結果
episode: 500/10000, score: -117.0, e: 0.95 @ 413 episode: 1000/10000, score: 6.0, e: 0.9 @ 83 episode: 1500/10000, score: -54.0, e: 0.86 @ 195 episode: 2000/10000, score: 8.0, e: 0.82 @ 73 episode: 2500/10000, score: 35.0, e: 0.78 @ 39 episode: 3000/10000, score: 31.0, e: 0.74 @ 61 episode: 3500/10000, score: 27.0, e: 0.7 @ 57 episode: 4000/10000, score: 34.0, e: 0.67 @ 31 episode: 4500/10000, score: 32.0, e: 0.64 @ 39 episode: 5000/10000, score: 33.0, e: 0.61 @ 31 episode: 5500/10000, score: 42.0, e: 0.58 @ 27 episode: 6000/10000, score: 40.0, e: 0.55 @ 19 episode: 6500/10000, score: 40.0, e: 0.52 @ 27 episode: 7000/10000, score: 37.0, e: 0.5 @ 27 episode: 7500/10000, score: 39.0, e: 0.47 @ 27 episode: 8000/10000, score: 39.0, e: 0.45 @ 19 episode: 8500/10000, score: 32.0, e: 0.43 @ 35 episode: 9000/10000, score: 42.0, e: 0.41 @ 21 episode: 9500/10000, score: 43.0, e: 0.39 @ 17
収束してる。精度はあまり変わってないような気がする。
中間層を2つ足した
def build_maze_solver(): model = Sequential() model.add(Dense(128, input_shape=(2, 2), activation='tanh')) model.add(Flatten()) model.add(Dense(128, activation='tanh')) model.add(Dense(128, activation='tanh')) model.add(Dense(128, activation='tanh')) model.add(Dense(128, activation='tanh')) model.add(Dense(1, activation='linear')) model.compile(loss="mse", optimizer=RMSprop(lr=LEARNING_RATE)) return model
結果
episode: 500/10000, score: -447.0, e: 0.95 @ 965 episode: 1000/10000, score: -24.0, e: 0.9 @ 137 episode: 1500/10000, score: 27.0, e: 0.86 @ 47 episode: 2000/10000, score: 24.0, e: 0.82 @ 45 episode: 2500/10000, score: 19.0, e: 0.78 @ 73 episode: 3000/10000, score: 41.0, e: 0.74 @ 27 episode: 3500/10000, score: 32.0, e: 0.7 @ 27 episode: 4000/10000, score: 41.0, e: 0.67 @ 21 episode: 4500/10000, score: 30.0, e: 0.64 @ 39 episode: 5000/10000, score: 40.0, e: 0.61 @ 23 episode: 5500/10000, score: 37.0, e: 0.58 @ 23 episode: 6000/10000, score: 40.0, e: 0.55 @ 25 episode: 6500/10000, score: 45.0, e: 0.52 @ 15 episode: 7000/10000, score: 40.0, e: 0.5 @ 19 episode: 7500/10000, score: 38.0, e: 0.47 @ 27 episode: 8000/10000, score: 40.0, e: 0.45 @ 27 episode: 8500/10000, score: 39.0, e: 0.43 @ 25 episode: 9000/10000, score: 39.0, e: 0.41 @ 19 episode: 9500/10000, score: 44.0, e: 0.39 @ 21
収束はしてるけど、これ以上増やしても無意味みたいな点がありそう
これ最終的なモデル実行時間が遅くなったりするんだろうか。
ゲーム用のエージェントを作るなら
ダイクストラと A* は何度も書いてるので、今回の題材は自分には理解しやすかった。
今回の迷宮(環境)は固定だが、与えられた任意の迷宮を解きたければ、たぶん、自分自身を中心としてゴール含むN*Nの相対座標系でクリッピングした行列を入力値に含む必要がありそう。そうするとめっちゃ入力値多い…
移動アクションの他、攻撃アクションを追加してみるとか、その際の彼我の HP の変動とかを入力に含んでみるとゲームっぽくなりそう。
どのへんまで環境変数増やすと計算爆発するとか収束しないとか、そのへんの勘所がないので色々試してみないとまだわかんなさそう。DOTA II のエージェントを作った論文があるので、それを読むといいんだろうか。
今の時点では、正直 keras の便利さがよくわかってなくて、直接 tensorflow 使うのとそんなに変わんなさそう。
python 久しぶりに書いた感じだと、スコープのガバガバさでイラッとする場面が多く、 let のような変数宣言がほしい気持ちになりがちだった。
React Hooks での状態管理と副作用の表現
React Hooks は Stateless Functional Component でも setState 的な状態操作や componentDidMount のような操作を可能にするための仕様提案です。
既に開発ブランチに入っていますが、 現時点で公式に採用されたものではないです。リリース時にはAPIが変わる可能性があります。
React のメイン開発者の一人である sebmarkbage の出してる RFC https://github.com/reactjs/rfcs/pull/68
試してみる
react@16.7.0-alpha.0 に既に実装されており、公式のブログでも解説が出ています。
自分は以下のように動作確認をしました。
yarn add react@16.7.0-alpha.0 react-dom@16.7.0-alpha.0 -D
import React from "react"; import ReactDOM from "react-dom"; const useState: <T>( t: T ) => [T, (prev: T | ((t: T) => T)) => void] = (React as any).useState; const useEffect: (f: () => void) => void = (React as any).useEffect; function Example() { const [count, setCount] = useState(0); useEffect(() => { const tid = setInterval(() => { setCount(s => s + 1); }, 1000); return () => { clearInterval(tid); }; }); return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> </div> ); } ReactDOM.render(<Example />, document.querySelector("#root"));
TypeScript で書いていたので、無理矢理、勉強がてら型をつけていて、その定義がこう。
const useState: <T>( t: T ) => [T, (prev: T | ((t: T) => T)) => void] = (React as any).useState; const useEffect: (f: () => void) => void = (React as any).useEffect;
setState
単純な更新部分から見ていきましょう。
function Example() { const [count, setCount] = useState(0); // ... return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> </div> ); }
ボタンをクリックするとカウントが一つ増えます。
挙動を見る限り、setCount が実行されると、この SFC が再実行されています。
内部的な話ですが、今までだと HoC で関数をラップして状態管理を外出しし、その setState としてラップされた SFC を再実行していたのが、HoC の助けを足りずに状態を持てるようになっています。これはライブラリ本体に手を入れないと実現できない挙動です。おそらく、実行コンテキストで登録されたリスナーとインスタンスの関係を結びつけているんでしょう。
uesEffect
useEffect は render とは関係ない副作用を記述するための機能です。
宣言的に開始処理、終了処理が書けます。
例1
setInterval 用のタイマーを登録する例
function Example() { const [count, setCount] = useState(0); useEffect(() => { console.log("start timer"); const tid = setInterval(() => { setCount(s => s + 1); }, 5000); return () => { console.log("stop timer"); clearInterval(tid); }; }); return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> </div> ); }
このコードでは、5秒に1回、値をインクリメントします。
これで気をつけるべきは setCount を呼ぶことで、useEffect の終了処理が呼ばれ、再実行されることでタイマー登録処理が再登録されます。
なので、この Click Me をクリックすると、setCount が呼ばれ、タイマーがリセットされます。なんでもいいから最後に更新されてから5秒後にインクリメント、が再定義されているわけです。
ここまで書いて気付いたんですが、一回実行されるたびに setiInterval は必ず、 clearInterval され、かつ再登録されるので、setTimeout でも全く同じ挙動になりますね。
useEffect(() => {
const tid = setTimeout(() => {
setCount(s => s + 1);
}, 2000);
return () => {
clearTimeout(tid);
};
});
この、「最後に実行されてからの effect だけ意識する」というのは、ちゃんと使う限りは副作用を起こすコードで意識すべきスコープを狭く出来て、とても良さそう。
例2
カウンタが奇数のときだけ useEffect を持つ Foo を表示してみます。
function Foo() { useEffect(() => { console.log("foo start"); return () => { console.log("foo end"); }; }); return <div>foo</div>; } function Example() { const [count, setCount] = useState(0); return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> {count % 2 === 1 && <Foo />} </div> ); }
ボタンを何度かクリックしてみたときの Console
foo start foo end foo start foo end foo start foo end
再更新だけではなく、外からアンマウントされる際のデストラクタでもある、という感じですね。 componentWillUnmount のように使うことができるという感じ。
useReducer
setState の reducer 版
型はこんな感じ
const useReducer: <T, A>( reducer: (s: T, a: A) => T, t: T ) => [T, (action: A) => void] = (React as any).useReducer;
コード
type State = { count: number; }; type Action = | { type: "reset"; } | { type: "increment"; } | { type: "decrement"; }; const initialState: State = { count: 0 }; function reducer(state: State, action: Action): State { switch (action.type) { case "reset": return initialState; case "increment": return { count: state.count + 1 }; case "decrement": return { count: state.count - 1 }; } } function Counter() { const [state, dispatch] = useReducer(reducer, initialState); return ( <> Count: {state.count} <button onClick={() => dispatch({ type: "reset" })}>Reset</button> <button onClick={() => dispatch({ type: "increment" })}>+</button> <button onClick={() => dispatch({ type: "decrement" })}>-</button> </> ); } ReactDOM.render(<Counter />, document.querySelector("#root"));
第三引数を渡すと、それを元に初期化する。
const [state, dispatch] = useReducer(
reducer,
initialState,
{type: 'reset', payload: initialCount},
);
これは reducer の function reducer(state = initialState, action) {...} の initialState の部分を外出しできるって感じっぽいですね。
全体的に、initialState を受け付けるが、 state 自体は外部にメモ化されていて状態を持ってる、って感じですかね。個人的には常に initialState を受け付けてるように見えて、あまり直感的ではないような気も…。
他のヘルパ
- useMemo
- useCallback
- useRef
- useImperativeMethods
- useMutationEffect
あとでちゃんと勉強する
感想
ライブラリでは表現できない、React 本体だから実装できる感じの API だと感じます。 class extensds React.Component の API あんまりつかってほしくなくて、SFC で全部が表現できるようにしようってのを感じますね。React コアチームは HOC と redux 嫌いそう。
記述の自由度、奔放さが上がる代償に、行儀が悪いコードも沢山かけてしまうよなーという印象もあります。 メモリリークなく useEffect を正しく使うには RAII ちゃんとやるみたいなのを徹底しないといけないので。
useEffect は宣言的な React から抜け道を用意する感があって、ちょっと怖いですね。
Issue 見る限りは、 hot reload どうすんの?みたいな質問とかがあって、確かに既存のは動かなさそう。
Mac で pyenv / pipenv の環境を作って keras 動かすところまでのメモ
tensorflow.js で遊んでたら keras でモデルを作って import してみましょうみたいな章に差し掛かったので、python の環境構築した。
TensorFlow.js tutorials - import-keras
環境構築
keras ついでに pyre を試してみたいので、 pyre で keras が書ける、というところをゴールにした。
pipenv は ruby の bundler みたいな体験を目指して入れてみた。
ググってみると Mac で Anaconda は地雷みたいな意見が多かったので、とりあえず homebrew から pyenv と pipenv を入れて、pyenv から python を管理することにした。
brew install pyenv brew install pipenv
export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"
自分は POSIX 非互換の fish を使ってるので ~/.config/fish/config.fish に以下を追記
set PATH $HOME/.pyenv/shims $PATH eval (pyenv init - | source)
ここで、 xcode-select --install して、 pyenv install 3.7.0 とすれば python が入るらしいが、自分の環境では次の記事と同じ問題が起きた。
pyenv install 3.6.6 でエラーが発生する。 – digitalnauts – Medium
おそらくだが、自分が homebrow を ~/brew にインストールしている関係で、python-build が期待してる環境変数からずれてしまってそう。
結論から言うと、上記の記事と同じように、色々と環境変数で渡すとビルドが成功した
# python 3.6/3.7 install $ CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" \ LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" \ PYTHON_CONFIGURE_OPTS=--enable-unicode=ucs2 \ pyenv install -v 3.6.6 $ CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" \ LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" \ PYTHON_CONFIGURE_OPTS=--enable-unicode=ucs2 \ pyenv install -v 3.7.0
keras 起動まで
3.6 と 3.7 を入れた理由だが、 python 3.7 で async が予約語になった関係で、 tensorflow のコード中にある async 変数でパースエラーになる。なので python 3.6 を使う必要がある。
Unable to install TensorFlow on Python3.7 with pip · Issue #20444 · tensorflow/tensorflow
$ mkdir try-keras $ cd try-keras $ pipenv --python 3.6 $ pipenv install tensorflow $ pipenv install keras $ pipenv shell $ python --version # => 3.6.6
コードを書く
src/hello-keras.py
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
$ python src/hello-keras.py Using TensorFlow backend. Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz 11493376/11490434 [==============================] - 6s 1us/step
動いた。
pyre-check を動かしてみる
Python 3 系は型の構文が予約されてるが、処理系にバリデータがあるわけではない。
その Type Checker の実装に mypy と pyre がある。 JS の flow と同じ作者の雰囲気を感じるので、今回は pyre を使った。
$ pip3 install pyre-check $ mkdir try-pyre $ cd try-pyre $ pyre init $ mkdir src $ vim src/hello-pyre.py # type your code $ pyre --source-directory src check ƛ Setting up a .pyre_configuration file may reduce overhead. ƛ Found 1 type error! src/test.py:2:4 Incompatible return type [7]: Expected `int` but got `str`.
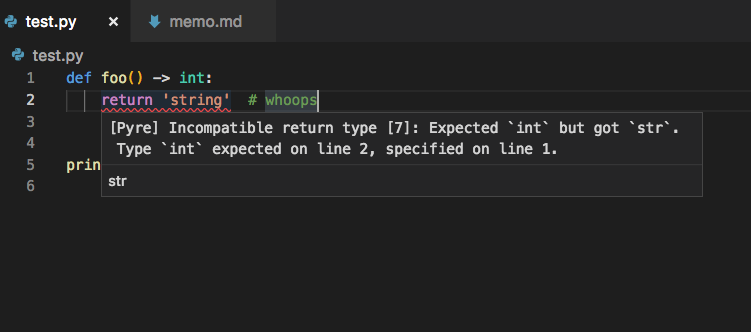
自分で書くコードに型をつけるには便利だが…
keras で使うと import path を知らないと言ってくるのを、だまらせる設定が必要だった。
こうするとさっきのコードに pyre-check が通る。
from keras.datasets import mnist # pyre-ignore (x_train, y_train), (x_test, y_test) = mnist.load_data() # pyre-ignore print(x_train)
結構だるい。mypy は 知らないモジュールの import を無視するオプションがあるらしいが、 pyre にはない。
(facebook はたぶん pytorch 使ってるんだろう…)
環境 & エディタ
vscode で python を開くと vscode が yapf を有効化する?ってきいてきたので、yes にしたら勝手にフォーマットされるようになった。便利
終わり
本記事と関係ないけど最初は Python でプログラミングを覚えたが、就活の頃(2012 年頃)全く python の仕事がなかったのと 2 系と 3 系の移行期で混乱していたので、 Node.js/JavaScript に切り替えた記憶がある。
昔も同じように環境構築で苦しんだ記憶があるが、その体験はあまり変わっていない。
MarkdownBuffer の実行時間の計測とパフォーマンスチューニングの余地
昨日作った mdbuf が 100000文字を超える場合、遅いときいたので、色々試してみた。
手元で18万のテキストを用意して編集してみた。それなりに重いが、それでもIMEを完全にブロックしてしまうほどでもない。とはいえイライラはする。
innerHTML で挿入にかかる時間を計測してみた結果、自分の手元では markdown 10000文字あたり、1.6ms の遅延。というわけで、体験を損ねない限界は 100000文字辺りが限界だと思う。とはいえ自分は最新モデルのMackbook Pro の中位ぐらいのモデルなので、平均的にはその半分の5万文字ぐらいだろうか。
ただ、画像がある場合には入力の度にリクエストが走ってるような気がするので、それのリサイズも合わさって、あまり良くない気がする。あとでアクセスがキャッシュに閉じてるか確認しておく。
細かい工夫として、IMEの変換中はプレビューの更新を止めてる。IME 変換中の不整合な状態を見たい人はいないと思う。日本語の入力はこれでだいぶ体験よくサボれる。
経験上、原稿書いてるときは多くても1万から2万ぐらいで別ファイル(章)に切ってるし、100000字はさすがにサポート外と言ってしまったほうが良さそう。基本的には20000文字ぐらいまでではないか。
でも将来的には大容量テキストをサポートしたいし、そのための実験を色々やった。
機能追加
- textarea 上で Ctrl 押しながらマウスホイールでプレビュー側を更新
- Tab/Shift+Tab でインデント
- プレビューが隠れている場合はレンダリングしない
スクロールシンクを実装しない代わりにマウスホイールで移動できるようにしたらめっちゃ便利でこれでいいじゃんとなった。
作図ツールが欲しくて、mermaid.js の組み込みやってみようとしたら remark-mermaid が fs 使ってて node 環境でしか動かないコードだったので、その部分を剥がして直接使えるか確認しに mermaid の SVG レンダラーのコードを読みにいったら、あまりに汚いコードで使う気が失せた。自分でそれっぽいの書くかも。
大規模な markdown 対応で、アウトラインへのジャンプはほしいかもしれない。そうしたら100000超えた際のサポートにも意義が出てくる。
textlint 組み込みをやろうか迷ったが、何入れても不満でそうで、汎用的なルールが思いつかなかったので後回し。
裏側で複雑な実装が増えてきたので、さっくりReact化しておいた。
実験
innerHTML への代入ではなく、差分レンダリングの仕組みを考えていて、手元で remark-react(preact) => worker-dom => MainThread での MutationRecord 適用というフローを試してみた。worker-dom 側での仮想DOM生成はうまくいったが、逆にMainThread から Worker 側にデータを投げる仕組みが見当たらなくて、無理矢理パッチ当ててみたが、よくわからなかった。もうちょいでできるはずなので、後一日ぐらい調べる。
これがうまくいけば、更新された DOM へのスクロールを作れば、スクロールシンクも実装できる。
React でやってない理由として、仮想DOMは実DOMと色々紐付いているせいで Worker で生成/破棄が出来ない。これが理由で worker-dom と、その上で動くことはわかっている preact で調べていた。MutationRecord に対し react-reconciler で自前 renderer を実装するという手がなくはないが、実装量が半端ないのでやりたくない。
これらがうまく言っても、裏のスレッドを専有してる Markdown のコンパイル時間は何も解決しない。本当に大きなファイルの場合、適当な位置でテキストを分割して8スレッド並列でMapReduceするみたいなことは思いついたが、実装のだるさの割に報われなさそうで、まだやる気があんまない。
Rust で書いて wasm バイナリで高速化するという手もあるが、remark 相当の拡張性、便利さを再現できなさそう。面白そうなテーマではある。
大量のテキストを食っても速い Markdown Editor 作った
もう人生で何個目かわからない markdown エディタ作った。が、今回のは結構気に入っている。
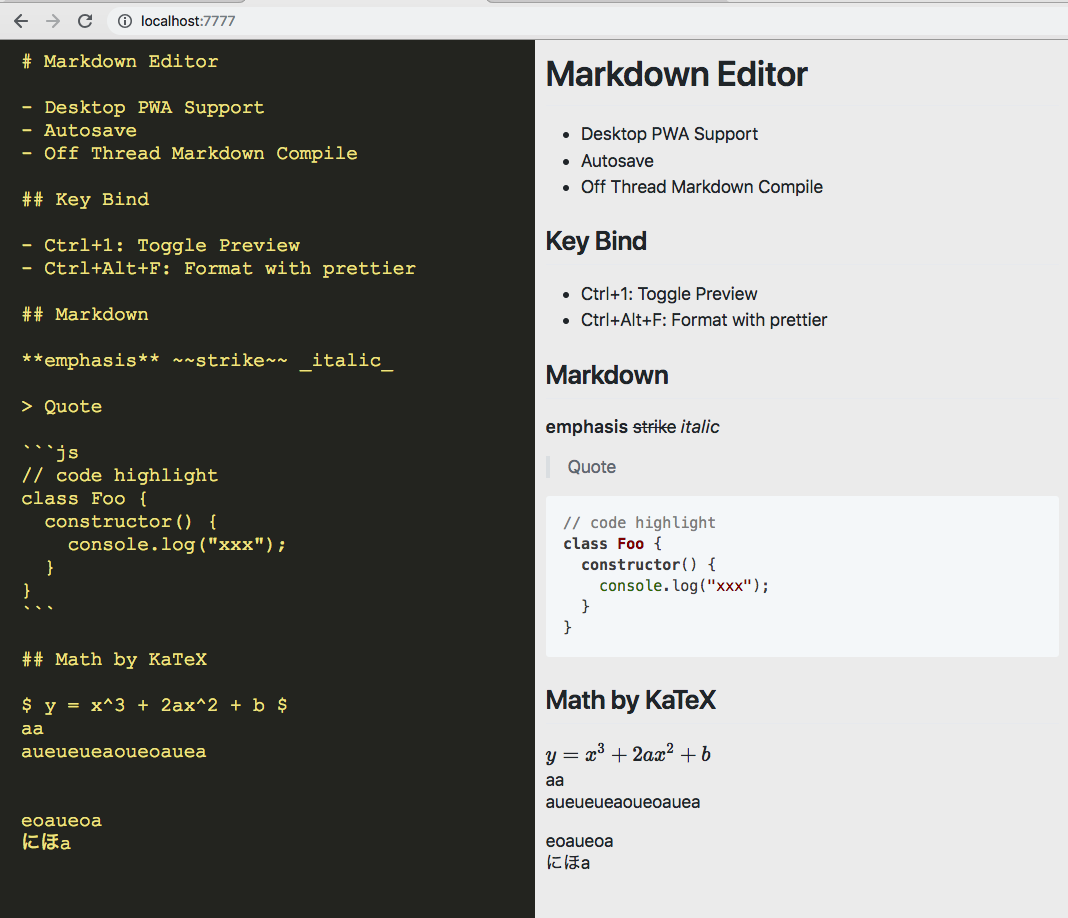
https://markdown-buffer.netlify.com/ で遊べる。
用途としては、GitHub か Qiita か はてなブログかわからないが、なにか書こうと思ったときに、どのサービスも中途半端に重いので、とりあえずのバッファが必要、という感じで作った。なので速度重視。
ブラウザのストレージで永続化してる。オフラインで動く。できるだけエディタとしてはスコープを大きくせず、単に編集バッファ(textarea)でしかない、というのを意識している。
結構頑張って作り込んでしまった https://nedi.app が色々肥大化してしまっていて入力時にラグを感じるので、編集体験を見つめ直す自戒もある。
機能
- 数式対応
- コードハイライト対応
- バックグラウンドで自動保存
- 改行を br に(line-break)
- Desktop PWA 対応 (chrome://flags から有効化)
- Ctrl+Alt+F で Prettier
- Ctrl+1 で プレビューをトグル
- WordCount 機能
スクロールシンクを実装してない。厳密にやろうとすると面倒なので後回し。
off-the-main-thread
メインスレッドのパフォーマンスをかなり意識した。
たとえば、なぜ仮想DOMという概念が俺達の魂を震えさせるのか - Qiitaの markdown、8000字程度を remark でコンパイルするのに、メインスレッドで 23~40ms 掛かる。これは一文字打つたびに、実際にもたつきとして感じられる。
これを WebWorker に逃がすことで、メインスレッドで入力中は全くラグらなくなった。
DevToolsのフレームグラフみても全然負荷掛かってない。
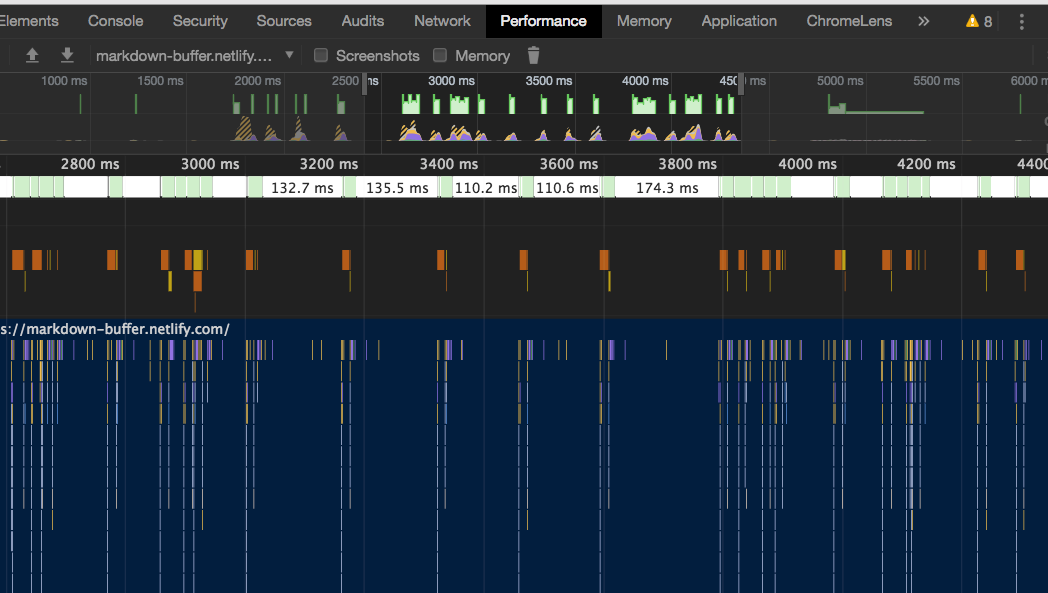
その代り、postMessage が往復する時間で 4ms x 2 ぐらいのプレビューの遅延が発生した。0.5フレームなので人間が意識するのは難しい。
バックグラウンド側のスレッドの初期化がチョット重いのだが、これは prettier/standalone のせいで、ただこいつを入れた結果ブラウザで prettier 使えるようになったので、まあいいかという感じ。もっとグレースフルに初期化する方法もあるが、そこはサボった。
使ったライブラリ
https://github.com/GoogleChromeLabs/comlink を使って postMessage をラップした。とても使いやすかった。
WebWorker 側だと localStorage に触れず、 IndexedDb を使う必要があったので、https://github.com/dfahlander/Dexie.js を使った。
remark の設定
このエディタでの書いたものを、外に持ち出したい場合の remark
import "github-markdown-css/github-markdown.css";
import "katex/dist/katex.min.css";
import "highlight.js/styles/default.css";
import remark from "remark";
import math from "remark-math";
import hljs from "remark-highlight.js";
import breaks from "remark-breaks";
import katex from "remark-html-katex";
import html from "remark-html";
const processor = remark()
.use(breaks)
.use(math)
.use(katex)
.use(hljs)
.use(html);
const html = processor.processSync("# Hello!).toString()