離婚します
最初に言っておくとmizchi と syake の 離婚はお互い嫌いになったという理由ではなく、単に結婚に求めるものが違っていて、その齟齬が顕著になった、ということに尽きます。
mizchi と syake は離婚しても友人であり、一緒にイベントなどもやる予定があります。これからも仲がいい友人であり続けるために適切な距離が必要になり、それには婚姻契約や同居がお互いにとって邪魔になったよね、という同意に至りました。
この2年間は本当に楽しかったです。結婚前にあった課題感、「エンジニアとして似たようなサイクルを繰り返すだけの予測可能な人生を打破したい」という当初の目的も達成できました。自分と違う人間と生活することで、様々な局所最適に陥っているのを自覚できるようになりました。これについて、syake には本当に感謝しています。
これ以上詳しいことを知りたい人は、Twitter で「ワインと鍋」に誘ってください。僕と syake 二人で通った、愛着がある店です。
syake 視点
2021年のまとめ・反省
年内に間に合わなかった…
2021年に主にお世話になった言語・ライブラリ
とりあえず挙げてみたが、なにか特定のライブラリを使う、という感じではなく、レイヤーが一つ下にいった感じがあり、実際にはなんかもうちょっと下のミドルウェアみたいなものを作っていることが多かった気がする。ASTをいじるコンパイラ周辺ツールを作っていることが多かった。
サクッとなにか作る場合、 React + TypeScript + Vite(esbuild) が鉄板という感じで、 esbuild が異次元に速すぎて、typescript の変換もバンドルも、もはやこれ一本でいい気がしてる。 microsoft/typescript はもはや言語仕様の定義と型検査がメインであって、コンパイルは別の実装に任せたほうがよさそう。
2021 年は Next.js も Webpack もほとんど使っていない。 Next.js に興味がなくなったわけではなく、自分の扱う範囲だとさくっとプラグインを書けて、都度細かくチューニングができる vite のほうが合っていた。 とはいえ No bundle の体験が良すぎるのもあって、webpack も基本使わなくなったし、世代交代を感じている。 webpack はプラグインを書く際の挙動の確認が大変で、あまり深入りしたくない。コードもしんどい。
Remix も気になってはいるのだが、同じ作者の react-router に嫌な記憶がありすぎて気が進まず、触れていない。あと、何度も Edge Worker が来る、来るといいつつも、自分で触ることができていない。
今後の予想と自分が力を入れたい範囲
Rust+Wasm がとても完成度が高く、これでフロントエンド周りのツールチェインが段階的に書き直されるのがほぼ既定路線。
rustwasm/wasm-pack: 📦✨ your favorite rust -> wasm workflow tool!
フロントエンドは下回りを全部 Rust で書き直すトレンドが続きそうで、 vercel, deno, rome あたりがキープレーヤーになりそう。vercel は特に人材が集中している。
Vercel welcomes Rich Harris, creator of Svelte – Vercel
Rust+Wasm はまだ Deno 周辺を中心にツールチェインを部分的に置き換えている段階だが、 dynamic link の仕様が落ち着いたらフロントエンドでも小さなライブラリを置き換えていく感じになると思う。
https://github.com/WebAssembly/tool-conventions/blob/main/DynamicLinking.md
フロントエンドの Rust はおそらく初期段階では特定のライブラリ作者が書くもので、誰でも書くというものにはならないと思っている。が、段階的にフロントエンド側にも Rust のコードが露出してくるだろう。
個人的にも Rust を暇を見つけて勉強しているが、まだ書きたいコードを書けるという状態には至っておらず、無理やり実戦投入する場所を見つけたい。
Edge Worker はユースケースが増えてきたが、まだ普及に至ってるとは言い難い。実際会社で何度か使おうとしたのだが、まだ k8sのような柔軟な権限やネットワークの構成ができないし、インフラエンジニア向けに Edge Worker でないといけない必要性をうまく説明できていない気がしている。Edge Wokrker の CDN のパフォーマンス特性が非機能要件なので、パフォーマンス面での訴求を行わないといけない。
Deno はまだ小回りが効かないが、開発体験がかなりよくなってきた。来年ぐらいから本格的に本番環境に投入できる時代が来ると思うので、そろそろ本腰を入れたい。 node 12~ の ESM のネイティブサポート denoify などでを積極的に自作ライブラリは両対応していきたい。
それはそうと、自分は k8s 周りのキャッチアップが進んでなくて、触る際も社内にあるボイラープレートをコピペして改造する程度になってるのが良くない。 okteto あたりで素振りをしたい。
今まで Docker のパフォーマンスの劣化が嫌で node はネイティブに動かしていたのだが、 M1 Pro にして、 Docker というか lima がかなり高速になったので、これをメインに活用していきたい気持ちがある。が、まだ周辺ツールが追いついてない感覚もある。 deno を lima で動かそうとするとしたら linux-arm64 バイナリがなくて動かないとか。
作ったもの: ブラウザ完結型フロントエンドに向けて
フロントエンドの開発はブラウザで完結すべきだ、という持論があり、今年もそれを個人的に研究していた。
この分野で今年一番の進歩は https://vscode.dev/ だろう。制限付きとはいえ、ブラウザで vscode が一通り動くようになったのは大幅な進歩。とはいえ部分的にビルドして使うみたいなのはまだ難しそう。
自分が今考えているのは、ただ monaco-editor のようなコードエディタをもってくるだけではなく、プログラマと非プログラマをつなぐものを作るべきだと思っていて、AST からノーコードインターフェースを生成するのを何パターンも試作している。
一昨年作った mizchi/vistree もそうだし、https://github.com/mizchi/tsx-source-jump は視覚的なUIとコードの対応をとるためにつくったもの。 6kb の typescript コンパイラである https://github.com/mizchi/mints は、そのままだとブラウザで typescript が動かせないので、service-worker に仕込んで透過的に ts を書けるようにするために作った。typescript は重すぎるので、runtime に仕込める程度の最低限のサイズにした。
vscode.dev を見て、 mizchi/file-system-editor でローカルファイルを全書き換えするのが Chrome 限定で可能なことを確認した。file system api の最初のバージョンではできなかった気がしたが、どこかでAPIが拡張されたのだろうか
tsx-source-jump の構成技術と file-system-api を使えば、ブラウザ内で自己書き換え機能を備えた React Component が作れる気がしていて、近々試作するつもり。
ブラウザ上で node を動かすカーネル周辺を実装する stackblitz/webcontainer-core は期待していたが、どうやらカーネル相当の実装がソース非公開でプロプライエタリなものになりそうで、もはや自分で作るしかないのではないか? と思い始めている。
正直ブラウザで動かすのは node.js より Deno のWeb標準志向のセマンティクスが有用だと思っていて、 mizchi/frontend-deno というのを試作した。これは mints を service-worker に仕込むことで、 deno 用のTSのコードがブラウザでそのまま動くことを実証した。
低レベルの必要性
暇を見つけては Rust や Wasm の仕様を読んだりしてみたが、自分が CS どころか基本情報レベルの概念を理解してないのを IEEE 754 とか LEB128 がリファレンスなしで出てくるたびに感じている。詰まるたびに妻に聞いてそんなのもわかんないの?これだからフロントエンドは〜とバカにされている。
とりあえず下回りからと、 https://store.steampowered.com/app/576030/MHRD/ で全加算器まで作ったりした。(そこで飽きた)
https://github.com/jlongster/absurd-sql を調べる過程で Atomics のドキュメントを読んだ際も、ただ wait と notify が futex のセマンティクスであるとだけ書いてあり、 futex は mutex のマルチスレッド応用ということはわかったが、ここから先はデータベースを自作するなどして肌感を掴む必要があると感じて、一旦後回しにしている。
仕事では主に 3rd party script に関わる仕事をやってるのだが、そこでも高速化のためになんらかのバイナリに圧縮したりすることが多く、枯れた gzip や deflate、最近だと cbor を脳死で採用しがちで、状況に応じた効率的なメモリ配置や圧縮アルゴリズムを選択できていない感覚がある。
CBOR — Concise Binary Object Representation | Overview
自分が低レベルな操作になれていないので、 ArrayBuffer と DataView を通じてデータ構造を変更するのに毎度詰まっている。JSでバイナリを操作する系の Web の資料は node の Buffer を使ったものが多く、ブラウザでやろうとすると UInt8Array/UInt16Array で書き直すことがとても多い。ブラウザで動く Buffer のポリフィルはビルドサイズが大きく採用できない。
JSのビット操作の演算子にまだ抵抗感があるが、一つ一つイディオムとして覚えると便利、という感覚を得られてはいる。とはいえなぜJSでやってるんだ感もある。
というか、 cbor や wasm や http3 がそうなのだが、 Web が全体的にテキストからバイナリに回帰している感がある。
親知らずの話
突然だが、今年の後半は体調を悪くしがちで、一番つらかったのは親知らずの抜歯(右側8番水平埋伏智歯)に伴う体調悪化だった。8月ぐらいから今までずっと続いている。
ただの親知らずの抜歯ではなく、最初は 3年ほど前に近所の歯医者で抜歯に失敗した。その後何度か引っ越しをはさみ別の歯医者に行っていたが、特に指摘されず、最近になって抜歯(失敗)痕が悪化していることを指摘され、総合病院の歯科口腔外科を紹介された。
歯科口腔外科の抜歯も失敗し、3回目に全身麻酔下でやっと抜けた。歯科医曰く、十数年に一度の難症例とのこと。
3回とも抜歯成功/失敗に関わらず、顎が腫れ上がるのと舌の筋肉の炎症で発声が困難になり、炎症で熱も出て一週間ほど寝込むことになっていた。ひどいときは口が 1cm ほどしか開かず、物理的に食べ物が口の隙間を通らない(看病してくれた妻に感謝)。経過観察でギターのカポのような謎の金具で口をこじ開けられたときは死ぬかと思った。
治療は終わったはずだが、現在でも歯根の一部が組織内に迷入している。おそらく影響はないはずだが、仮に影響が出た場合、それはもはや歯科口腔外科ではなく ICU で脳外科に近い治療になるとのこと。
また、治療後にめまいが続きなかなかコードが書けず、それで仕事の進みが悪く、結構凹んでいた。歯科口腔外科の先生に相談したら、精神的なものもあるので、そうやって気に病むのもほどほどにしたほうがいいとアドバイスを受けた。
コロナには罹ってないが、ワクチン二度目の接種で異物混入ロットを引いた。
モデルナ製ワクチンの異物混入について 墨田区公式ウェブサイト
歯科口腔外科の先生には、あまりにも珍しい事例を連続で引いたので、「今年宝くじ勝ったら当たるかもよ」と謎の励ましを受けた。結局買っていない。
モデルナのワクチンの副反応も結構しんどかった記憶があるが、親知らずのインパクトが強すぎてよく思い出せない。
おわり
全体的に体調悪くてあんまり動けなかったという反省があり、 2022 年はいい感じにしたい。
2020年やったこと、考えたこと、触った技術のまとめ
今年の本業は、 3rd party script で、そこから呼ぶウィジェットを最適化するコンパイラを書く、その仕様を考えて、実装するという感じだった。要は Google Analytics と、最適化コンパイラ付き GTM みたいなものを作っていた。その内容は以下に書いた。
パフォーマンス改善に Core WebVitals という大義名分を得た
今年は、 パフォーマンスのエンジニアをやっていた、と思う。サードパーティスクリプトの配信を生業にする会社のエンジニアとしては、来年の Core WebVitals というパフォーマンス関連の大きな変化で、波にのってやりたいことがやれたと思う。 Core WebVitals の導入で実際にどれぐらいの影響がでるか不明だが、パフォーマンスが SEO に影響する、というのは、 若干やりすぎと思いつつも、 Google の目指す Web の世界観と、モバイルがメインとなったエンドユーザーの体験にとって両方大事なもので、とくにフロントエンド周りで富豪的なプログラミングを常態化しつつあったエンジニアコミュニティの開発スタイルに一石を投じるものではあった。
大義名分として利用はしているが、SEO最適化そのものを目的にするのではなく、コンテンツしかり、ユーザーの体験を最適化すると、それが評価される、というのは正しい世界観であると思い、同調している。Chrome に組み込まれている Lighthouse は Idiomatic な計測ツールだが、他のツールが有意義な指標を出せてない以上、まずこれに従うべきだと思っている。そのための根拠は一応提示されている。
Next.js 再評価と Lighthouse
Web の最適化を考えることで、自分は Next.js を再び強く評価するようになった。
Core WebVitalsの指標は、フロントエンドの改善に目がいきがちだが、ある程度やるとサーバーサイド込みで改善が必要で、その最適化をある程度以上すすめるには、現状 Next.js のようなクラサバまたがる最適化が必要、という認識を持った。
Lighthouse の意義は、パフォーマンス最適化を、スコアによってゲーミフィケーションしたことだと思っていて、これによって今まで意識することが少なかったパフォーマンスや、アクセシビリティに開発者の意識を向けることに成功している。
Lighthouse によって、手軽にフロントエンドのISUCON的なことができるようになった。お題は無限にあるので、まずは自社の重い画面を分析してみるとよいと思う。
現時点のベストプラクティスは静的サイトの動的更新の JAMStack であると認識しているが、CI を通って更新するので、コンテンツの更新が遅く、 そうでない場合は Next.js + ISR がイケてる。
ただし、これも結果整合で Edge Cache の不整合が発生するので、運用者にそれの説明コストを払う必要があったり、事故ったりした際のリカバリがきつそうな気もしている。
そのへんで期待してるのが Cloudflare Workers 関連のプロダクトで、 CDN Edge でJSでロジックを書いて、素早いキャッシュパージができる。
現状でも Fastly VCL でも可能なのだが、 Fastly の仕様にロックインしてしまう。現時点で自分は Fastly に賭けるみたいな判断・覚悟ができてないため、次の仕様が普及することを期待している。
Fastly は確かにすごいのだが、これに詳しくなると Fastly でしかフロントエンドが作れない人間になってしまう危機感が常にあって、なかなか手が出ない。
日経電子版のチームはFastlyがっつり使いこなしていてすごい。会社としてロックインする、みたいな覚悟がないと、これはできない。
サードパーティスクリプト改善への取り組み
自分の仕事としては、 3rd party script というテーマがなかなか面白くて、ITP や GDPR がある環境の中、いかにパフォーマンスに配慮しながら、かつ 3rd という限られた環境で、いかにメインスレッドを専有せずに自分のタスクを遂行するか、ということをずっと考えていて Web Worker (Dedicated Worker) を使ったフロントエンドののプログラミングスタイルを試行錯誤していた。
その中でもとくに、 comlink インスパイアで作った minlink という自作ライブラリが、メチャクチャ小さいサイズながら、よく動いていて、自分でも気に入っている。 node の worker-thread の勉強も兼ねて、 node 対応もしてある。
- Web Worker の使用 - Web API | MDN
- off-the-main-thread の時代 - mizchi's blog
- mizchi/minlink: Minimum(> 1kb) and isomorphic worker wrapper with comlink like rpc.
今年前半部の反省なのだが、3rd party script の一部に、自由文脈記述のウィジェットを配信するみたいなものがあるのだが、パフォーマンス意識するあまり、コーディング規約を増やしすぎて、クリエイティビティを疎かにするような仕組みを作ってしまった。 最初は preact + css in js, terser で treeshaking + Dead Code Elimination を有効にする書き方を推奨するつもりだったが、何人かに書いてもらってみて、それを意識してコードを使いこなせる人間は、あまりにも少ないことがわかった。
terser のデッドコード検知はかなり賢いのだが、それは書き手が terser のコード畳み込みを意識して書いた場合に発動するもので、自由奔放に書いてもコードが削れるものではない。Terser REPL で色々と試した結果、そういう認識になった。
そこでたどり着いたのが svelte + svelte-check で、 元々は Svelte の TypeScript 対応という触れ込みで触ってみたのだが、 CSS と JS の変数で、デッドコードへの警告が出せたり、アクセシビリティの警告が出せる、ということがわかった。
下手に DCE を意識してコードを書くより、CIを通して未使用コードを検知できる仕組みが作れた。
いろんな賢い仕組みを作ってみたが、結局「生産性やクリエイティビティを犠牲にしてパフォーマンスを選択する」ということは不可能で、仕様を作る人間としては、それを意識させない仕組みを提示する必要がある。svelte は小さいビルドサイズながらなかなかリッチな表現形態を持っていて「ライブラリではなくコンパイラ」という思想をよく体現している。
rollup と svelte は webpack と違って ブラウザで動かせるので、 rollup を svelte コンパイラ込みでクライアント向けにビルドして、サーバーを介さない、高速なプレビューを実装できた。そこは OSS にしてある。
今年は、 svelte と rollup という Rich Harris 製の OSS にお世話になることが多かった。
browserify の Node.js エミュレータという世界観で始まったフロントエンドビルドツール界隈だが、ES Modules がすべて、という世界観によって、 Node.js の一強という世界観が薄れて、 Deno や Skypack が台頭しつつあるように感じる。
IE との付き合い方
IE との付き合い方を、今までとは根本的に発想を変えた。IE でも動く水準で仕様を考えたりコンパイルするのではなく、いかにIEを意識せずに仕様を決めるかを意識した。
その上で IE を別系統でビルドして、メインストリームの開発環境からIEに縛られているという悪影響を排除するか? という考え方をするようにした。
2020年時点でたった 4% の IE に発想を縛られるということが悪だと思っていて、モダンブラウザ向けに仕様を考えたあと、いかにIEで再現できるか、というステップを踏むことにした。
それで作業量が減ったかというと、結局は別系統のビルドができてしまい、その関係で IE 対応に 1ヶ月ぐらい時間を使ったりしてしまったので、作業工数としてはやはり見積もりづらく、辛い。早くIEのことを考えない世界に行きたい。
来年の話
反省点として、実際にフロントエンドの問題だと思って取り組んだものが実際にはサーバーサイドの問題だったことがあった。フロントエンドの問題を潰したことでそれが浮かび上がったので、フロントエンドの改善には一定の意義があったのだが、実際には DataDog APM を見る必要があった。
フロントエンドや埋め込みタグというテーマだったせいか、マイクロチューニングにばかり詳しくなってしまい、来年は datadog も合わせてサーバーサイドと合わせて多面的にパフォーマンスを計測できるようになりたい。
結局、 Next.js フルスタックが必要だ、と思ったのも、Core WebVitals のパフォーマンス改善でクライアント・サーバーを複合的に見れる人が少ない、という問題意識がある。自分もミスをしたので、パフォーマンスのエンジニアを名乗るにはまだまだ未熟で、精進が必要だと思う。
フルスタック Next.js 調べるのに、最近データベース周りを調査していて、最近 postgres が熱いのでは、と気づいた。主に create trigger のリアクティブ性によって、新しい発想のフレームワーク・ライブラリ・環境が出現してきている。
- CREATE TRIGGER
- supabase/supabase: Website, docs, and examples. Follow to stay updated about our public Beta.
- Materialize – A Streaming Database for Real-Time Applications
- Hasura | Instant GraphQL APIs for your data | Join data across databases, GraphQL & REST services to build powerful modern applications
最近、というか年末年始は、Next.js の本を書く予定。ただ最近、 among us と スターデューバレー 1.5 にハマってしまったため、年末年始に書き上がるかは、それらがどう転ぶか次第。
他細かいやってたこと
- vue
- k8s
- kustomize など
- チームメンバーが詳しいので、もっぱらコンテナハッシュを更新するという体験
- 個人で学習用クラスタを建てたが、高いので閉じてしまったどうにかしたい
- Chakra UI
- React で Tailwindみたいなユーティリティ指向のコンポーネント書く時にめっちゃ便利
- tailwind 自体は、なれてないせいもあるかもだが、なんか肌になじまない
- AMP
- 調査対象
- Google Analytics
- 調査対象
- タグの実装はいいとして、管理画面複雑すぎる。データ分析用の仮説が Analytics 側で存在してそのフレームワークに乗ることを強制させられる。エンジニアとしては、関係で送ったデータがどこに保存されてるのか、まったくわからん
- Google Big Query
- 仕事
- 最近 snowflake が気になってる
- Google BigTable
- 仕事
- Google Cloud Pubsub
- 仕事
良いお年を
リングフィットアドベンチャーをクリアして 8kg 痩せて筋肉質になった (71kg => 63kg)
ちょっとはてなブログを放っておいたら90日以上進捗がない人の広告が出るようになってしまい、最近やり続けたことといえばリングフィットなので、その話。
(ちなみに、最近このブログの投稿数が減っていたのは、技術記事を別のブログ で書くようにしたからです)
クリア自体は 62 日目、今は 101 日目で二週目の後半。体重の変化はタイトルのとおりです。
ビフォアアフター
before

after

身長169cm なので 62.8kg が標準体重です。63kgなのでほぼそれぐらい。14年前の高校生以来の水準です。
体重がただ減っただけではなく、体全体がかなり筋肉質になっています。
ダイエットの動機
突然病気の話なのですが、去年の 12 月頃から 1 月にかけて長期間、体温が37.5度から下がらず、病院にいったところウイルス性肝炎に罹っていたことが判明。その後の精密検査で脂肪肝を指摘をされました。これらは個別の症状ではそこまで体調が悪化することが無いものの、肝機能の低下に肝炎が合わさると、肝臓の働きが追いつかないそうです。このウイルス性肝炎で一ヶ月ほど休職する羽目になりました…。
前にも糖質制限ダイエットで 82kg から 66kg まで痩せたことがあるのですが、このときに元々あったか脂質を過剰にとったのが原因で脂肪肝になっていたようです。
なので、今回は脂肪肝をなくすこと、健康に痩せることを目的としました。
リングフィットは、最初は買った当日だけやって放置していたのですが、コロナが流行り始めた頃から妻が毎日やるようになって、5 月あたりから自分もやるようになった感じです。
(2月に結婚しました)
リングフィットでのダイエットの先行事例
- switch のダイエットソフト 3 種を比較!一番痩せたのはこれ | SPOT
- オタクが週5で半年間『リングフィットアドベンチャー』を続けた結果、生み出されたボディが素晴らしいと話題 - Togetter
やったこと
- 毎日一時間、23~24時頃にリングフィット(90~130 キロカロリーの消費)
- 食事制限(脂質を抑える、糖質の分割摂取、食物繊維)
体調悪い日は休んでいましたが、基本的にはほぼ毎日1時間ほど。
妻目線の食事制限の詳しい内容は こちらのブログを参照。
コロナ禍の真っ只中、夫のダイエットに協力した話 - いくらどん
結果
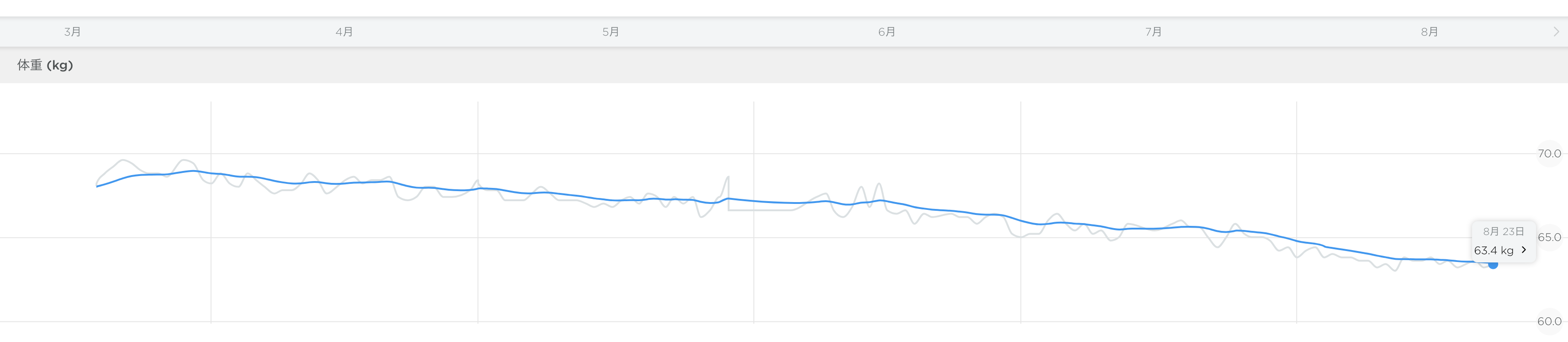
生データ
from:@mizchi source:IFTTT/ Twitter
胸筋のおかげで胸板が立体的になりました。サゲテプッシュのおかげだと思います。
妻曰く、いびきがなくなったそうです。
コロナの自粛期間のおかげで生活リズムが安定させやすかったです。会社は元々リモート可で、自分は 3 月以降、 1 日しか出社していません。出社してないのは、オフィスが銀座のど真ん中で危険なのと、妻に基礎疾患があるのが理由です。
リングフィットの感想
まず、リングコンの身体トラッキングやフィードバックがとてもよくできていて、とくに振動によって「鍛えてるぞー」という感覚が強くフィードバックしてくれるのがモチベーションに効きます。腕を振り回す系のスキルで、モンスターをしばいている感が出るのが楽しいです。
トレーニングのラインナップは全身鍛えられるようなものが揃っています。特にトライセプスがお気に入りで「上腕三頭筋ってそうやって鍛えるんだ…」という感覚が得られて良いです。肩こりなので無限にグルグルアームしていたいです。
序盤で脱落した人に伝えたいことなんですが、最初のスキルセットはゲーム内でも比較的きついものがセットされています。ヨッピーさんの記事でも指摘されていますが、スキル(トレーニング)のキツさと攻撃力が比例していません。なので、一周目の中盤以降は甘えがでて簡単なスキルでダメージを稼ぎがちになってしまうのですが、自分は逆にこれで挫折しそうなところでモチベーションの維持ができて長続きしたような気がします。終盤は肩こりに効く系のスキル(グルグルアーム、アームツイスト)が強く、助かりました。
2周目の今はむしろ刺激が欲しくなって、強くてきついスキルを半分ぐらい入れるようにしています。マウンテンクライマー、舟のポーズ、ワイドスクワット、レッグレイズなどですね。マウンテンクライマーはこのゲームで辛いスキル筆頭で、最初はこれを一セットやると力尽きて何もできなくなってしまうほどなのですが、今では一日あたりマウンテンクライマーを 5 セットほどできるようになりました。
このゲームで残念なのは、トレーニングしたい部位のスキルが弱い場合に選びづらいことです。序盤は同じスキルで飽きないようにという配慮からか、常に新しいスキルを試せるのですが、一周目中盤ぐらいから弱すぎるスキルがゲーム的に選べなくなってしまいます。とくにゲームシステム的に回復スキルが死んでいます。
シナリオは可もなく不可もなくという感じ。
次回作 & 後発の作品に期待すること
自分は Wii で発売された「斬撃のレギンレイヴ」というゲームが好きで、要は 「Wii リモコンを剣や弓に見立てた地球防衛軍」なんですが、巨人を剣で上下左右に斬りまくる運動は、中々の運動量がありました。こういう作品がもっと増えてほしいと思っています。ダイエットという文脈をどれほど汲むか、というのは難しいところですが…。
リングフィットは、ダイエットのためのゲームというのが強く打ち出されているのですが、いずれ飽きてしまう気がしてます。なのでもうちょっとゲーミフィケーションされた作品があると面白いですね。Fit Boxing は肌に合わなかったです。
運動量があるゲームだと、去年は VR の Beat Saber にハマっていて、 最高難易度の expert+ を全楽曲の半分ぐらいクリアしたところまでやりました。これもなかなか良いのですが、 結婚してからは一人で没頭する VR はちょっとやりづらいです。 Switch に移植できたらいいんですけどね…。
Beat Saber - Overkill - RIOT (Expert+)
(昔は最難関だった Overkill の Expert+。結局自分もクリアできてない)
リングフィットをより良くするなら、運動量のある Beat Saber みたいなスコアでゲーミフィケーションされた音ゲー、というのがたぶん自分好みそうです。どこか出してほしいですね。
おわり
60kgまでは続けるつもり。
ズンバとジャストダンスは、まだやってない。
俺の webpack.config.js-20200503
基本思想
- とにかく薄く。必要なものだけ。基本は ts-loader を
transpileOnly: trueで使うだけ。最悪これだけでいい。型チェックはIDEかyarn tsc -p . --noEmitでやる。 - CRA や parcel は使わない。暗黙な振る舞いが多すぎるので。一切勉強したくない人はいれていいと思うが、その場合 eject しない、dist ディレクトリをそのまま使うこと前提。
- style-loader/css-loader は外部CSSを読むときに設定する
- worker-plugin はなくてもいいけど、 worker もビルドしたいことが多いので、入れていることが多い
- html-webpack-plugin と webpack-dev-server 組み合わせると、他と組み合わせずに完結して動く。このHTMLを本番で使わずとも、デバッグで使ってることが多いので常に入れてる
- デフォルトの src/index をentry, dist/main.js を出力するのはそのままで、複数ファイルになったらいじる
期待している構造
src/index.ts(x) src/index.html package.json tsconfig.json --- ignore --- dist/* node_modules/*
install
yarn init -y # package.json がない場合 yarn add webpack webpack-cli webpack-dev-server ts-loader html-webpack-plugin worker-plugin style-loader css-loader typescript -D # or npm install --save-dev ...
webpack.config.js (最小)
module.exports = { module: { rules: [ { test: /\.tsx?$/, use: { loader: "ts-loader", options: { transpileOnly: true, }, }, }, ], }, resolve: { extensions: [".js", ".ts", ".tsx", ".json", ".mjs", ".wasm"], }, };
webpack.config.js (通常)
const path = require("path"); const HTMLPlugin = require("html-webpack-plugin"); const WorkerPlugin = require("worker-plugin"); module.exports = { module: { rules: [ { test: /\.tsx?$/, use: { loader: "ts-loader", options: { transpileOnly: true, }, }, }, { test: /\.css$/i, use: ["style-loader", "css-loader"] }, ], }, resolve: { extensions: [".js", ".ts", ".tsx", ".json", ".mjs", ".wasm"], }, plugins: [ new HTMLPlugin({ template: path.join(__dirname, "src/index.html"), }), new WorkerPlugin() ], };
tsconfig.json
module: commonjs だと tree shaking (未 import のコードを削る機能)が効かない。tree shaking するために、 module: esnext を設定する。
あと個人的には "moduleResolution": "node" と esModuleInterop: true も必須だと思っている。あとはお好きに。
{
"compilerOptions": {
"target": "es2019",
"module": "esnext",
"moduleResolution": "node",
"jsx": "react",
"strict": true,
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true
}
}
(大抵はnodeの細かいユーティリティ使うために yarn add @types/node もしている)
package.json scripts
"scripts": {
"build": "webpack --mode production",
"dev": "webpack-dev-server",
"typecheck": "tsc -p . --noEmit"
},
CI で typecheck を走らせる。watch ビルド時に常に型チェックするのはCPUの無駄。
dev では、html-webpack-plugin が入っているので、index.html も生成され、localhost:8080 でプレビューできる
(このとき index.html に entry の script タグが自動挿入されるので、書かなくて良い)
netlify にデプロイ
yarn build (npm run build) して、生成された dist をどこかのホスティングサイトにアップロードしたら終わり。
yarn build # 生成 npm i -g netlify-cli netlify deploy -d dist --prod
webpack のベストプラクティス、 ts-loader を transpileOnly: true で使う、ぐらいに落ち着くので、わかってる人ほど何も書くことがないのだと思う https://t.co/DqIKQJZLUS
— 滞納太郎 (@mizchi) 2020年5月3日
大抵の人はこれを使うとかでもいいじゃないかな。 "namics/webpack-config-plugins: Provide best practices for webpack loader configurations" https://t.co/KEyUoSZtwK
— azu (@azu_re) 2020年5月3日
Qiitaのランキングの最初の設計者としての「いいね」の設計と、「LGTM」は下においてほしいという話
https://blog.qiita.com/like-to-lgtm/
Qiitaさんの変更。思想はまぁわかるものの、「全部読んでから押してほしい」といいながら、開いた直後に押せるところに配置するのは意味がわからないかなあ。https://t.co/HEtwKg0txr
— chokudai(高橋 直大)🌸🍆🍡 (@chokudai) 2020年3月12日
これについては chokudai さんに完全に同意なのですが、その理由として、自分の在職時に企画したサービス設計意図が強くあって、退職者がそれについて今更どうこういうのはどうか思うところもあるのですが、当時の同僚がほぼ全員退職してしまっているため、ここでその意図を伝えます。
お前は誰 & 何
当時の Qiita の開発で、ストックといいねを分離して、いいねをベースにしたランキングの実装のを提案したのが自分です。社内の Qiita:Team にそのログは残っていると思います。3年前に退職しました。
いいね導入の際に、ユーザーの皆さんに混乱を招いたことは申し訳なく思っています。ただし、その時の「いいね」は自分の提案したものと、かけ離れた形で導入されており、その件についてこの記事で説明すると同時に、LGTM は末尾に置くべき、という主張をします。
自分が提案した総合ランキング/サブカテゴリランキング制度
5 年前、当時の Qiita は Google,はてブからの流入が多く(現在でも比率が高いはずです)、自力でユーザーの回遊を回せない、サービス内でエンゲージメントを高める動線が弱い、といった課題がありました。これは Google 側の SEO アルゴリズムの変更や、はてなのドメイン フィルタリングなど、なんらかの事情で Qiita への流入が絶たれると、サービスとして致命的である、 といった危機感です。
また、Qiita のサービスリリースの初期は機能していたタグ購読機能、ユーザーフォロー機能が、タグの多様化やコミュニティの肥大化で、あまり機能しなくなっていました。
そこで、ユーザーのエンゲージメントを上げる、つまり記事を書くやる気を出してもらう方法として提案したのが、ストックや閲覧数をベースにしたランキングシステムの導入です。その上で、総合ランキングのみでは、ノンジャンルで読みやすい「ポエム」が上がりやすくなってしまう(某壁問題)ので、タグの共起の相関クラスターなどを元にしたカテゴリ分類での、サブカテゴリのランキングの導入を提案しました。これはユーザータイムラインの代替として機能するはずだ、という意図です。
結果として、実装工数などの問題で、総合ランキングのみが導入され(これをテストリリースした段階で退職)、その後、後者は実装されませんでした。
時は経ち、 トップページのメインの動線が機能しなくなったユーザータイムラインから総合ランキングに切り替わったとき、当初懸念したとおり、技術的な実体のない「ポエム」系統の記事で上位が埋め尽くされる問題が加速してしまいました。
自分としては、これは当初提案していたサブカテゴリのランキング/あるいはクラスターのフォローの実装をしていれば防げたかもしれない問題だと思っています。(が、ちょっと自信無いです…)
いいねとストックの分離について
まず、Qiita には最初にストックがありました。これは「後で読む」ということを意図した機能です。なので、ストックは記事トップにありました。ランキング機能を作るにあたって、読まずにストックする可能性が高い「あとで読む」を転用すると、タイトル詐欺が加速する懸念がありました。
そこで、個人的な記事のストックとは別に、読み終わったあとの評価を分離した「いいね」の導入を提案しました。
もっというと、自分はストックは完全に不要な機能だと思っていました。個人のブックマークやソーシャルブックマークなどによって、それらは別途個々人がもっていたはずです。ただし、これは既存のユーザー の体験を壊すことになってしまうという yaotti の強い反対で、ストックの廃止は見送られ、ストックといいねが共存することになりました。(自分は今でもストックの存在は不要だと思っています)
その折衷案として、ストックは記事冒頭に表示するが、読み終わった人しか「いいね」を押せなくする、するという形で、いいねが実装されました。そしてランキングのソースはいいねを使うこととする、といった形になりました。
なので、いいねか LGTM かはどうでもいいのですが、記事の評価に対するフィードバックなので、そのボタンは末尾に置くべきだと思っています。読まずに LGTM を押す人が増えるという懸念です。
今のサービス設計から邪推してしまうこと
Qiitaは、基本的にいいねを押されるのが記事を書くモチベーションになっているプラットフォームです。だから、書き手のエンゲージメントを上げるために押しやすくしたいのは、とても理解できますが、タイトルだけで中身がいまいちなものが押されるようになると、その価値が失われてしまうのではないか、ということを伝えたいです。
報告: 結婚しました
なんか今日は2がいっぱいあるので @syakejs と入籍しました。
— ヌー (@mizchi) 2020年2月21日
以下例のリンクですhttps://t.co/dnzQMbvxdu pic.twitter.com/FrEcrOGUAz
私事ですが(と個人ブログでいうのもなんですが)、syakejs:(blog) と結婚しました。彼女は Webエンジニアだったり、大学でセキュリティの研究をしてたりしています。競プロやCTFもやってるらしいです。 話を聞いてみると、昔から僕のブログやTwitterをみていたファン?だったらしいのですが、最近なんやかんやあってコンバージョンしました。
入籍いつしよっかーという話になって、西暦2020年(令和2年)2月22日というゴロがよかったので、この日に決めました。
なにかしたからと言って別段何かが変わるというわけではなく、これからも普段どおりやっていくので、みなさんよろしくおねがいします。