フロントエンドの開発環境に Docker は不要(少なくともMacでは)
追記: 前提部分
開発環境を docker-compose で抽象することが最近のベストプラクティスだとされているが、フロントエンドをコンテナに突っ込むと無視できないIOボトルネックが発生する。
とくにwebpackのファイル監視からのビルドで発生する高頻度のIO処理を捌くために、フロントエンドだけはホスト環境に移したほうがいい、という主張。
これについて
自分の意見
- Web開発者の主要な開発環境である Docker for Mac は I/O がとにかく遅い (3x~5x)
- data volume の driver やら cache を工夫しても遅い
- npm install/webpack は 基本的に I/O ヘヴィー
- フロントエンドの最終成果物(.js, .css, .html)に環境依存なプログラムが含まれない(含まれてたらおかしい)
- そもそも JS という言語自体がクロスプラットフォームに配慮された言語なので、ホスト環境によるランタイム差がほぼない
ネイティブモジュール周りの既知の問題
- fsevents: webpack や chokidar などの裏側でファイルシステム監視を行うモジュール。npm の lockfile がビルドした環境次第で optional dependencies の native module をうまく依存に含めることができず npm install で再現されないことがある。ファイル変更監視が低速化するだけで動くには動く。yarn でこれが起きたことはない。
- node-sass: libsass の node バインディングだが、ややビルドが不安定。nodeのバージョン上げると大抵コケるのでキャッシュ捨てて再ビルドが必要。最近は css-in-js が流行ってるのでnode-sass見かけることが減った。
- node-gyp: node本体のビルドツール(python2)。 python3 にパスが刺さってる状態でネイティブモジュールをビルドすると失敗する。node でネイティブモジュールを使う環境は
pythonが python2 を指している必要があるが、これは他のビルドツールでも何かと要求される要件ではある。
これらを知っていればそこまでクリティカルにはならない。
運用どうするか
CircleCI、デプロイ時、初期セットアップの手数を少なくするためにとりあえずNodeイメージ経由でのフロントエンドのビルドタスクは用意する。開発環境では使わない。
他のプログラミング言語の人から本体のバージョンを固定することを強く要望されることがあるが(それらの言語が不安定なことが多い)、直近の Stable 使ってる限りは Node の実行に差が出ることは稀で、フロントエンドのビルドツールツェインに関してはそこはあまり抽象してメリットがあるレイヤーではない。が、自分の詳しくない領域の安心感がほしいのはわかるので、上述のビルドタスクを提供する。
node のインストールが困難な開発メンバーがいる場合はサポートする。たぶん二手ぐらいで終わるので、docker それ自体の導入より遥かに簡単。
Windows/WSL環境 の場合
すいません自分がWindowsでフロントエンド開発したことないです。
あんまり人権がある方ではないとは聞いてる。
サーバーサイド node の場合
他のサーバーサイドと環境と違ってビルドによる環境差がそこまでないので気にしなくていいと思っているが、 node はネイティブモジュールの数次第で、 imagemagick あたりが鬼門。こいつは常に鬼門。別環境に追い出したい。
node server を運用する際はこの限りではない。
というのが自分の意見です。
Chrome 73 で Desktop PWA Support & mdbuf アップデート
Signed HTTP Exchange もですが、個人的に待望だった Desktop PWA が正式リリース。 PWAアプリをウェブアプリのように振る舞わせることができます。
例えば mdbuf を開いて、「mdbuf をインストール」を選択すると…
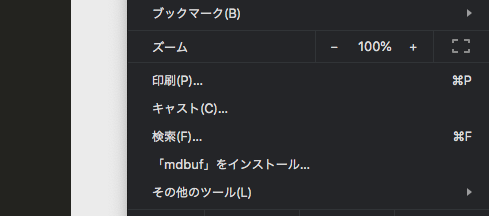
モーダルが出て
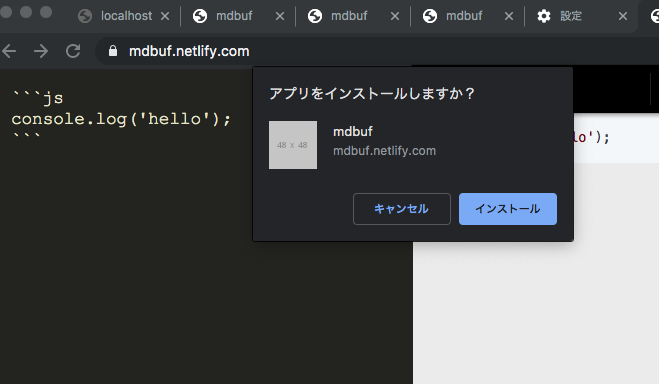
Win/Mac のアプリのように立ち上がります
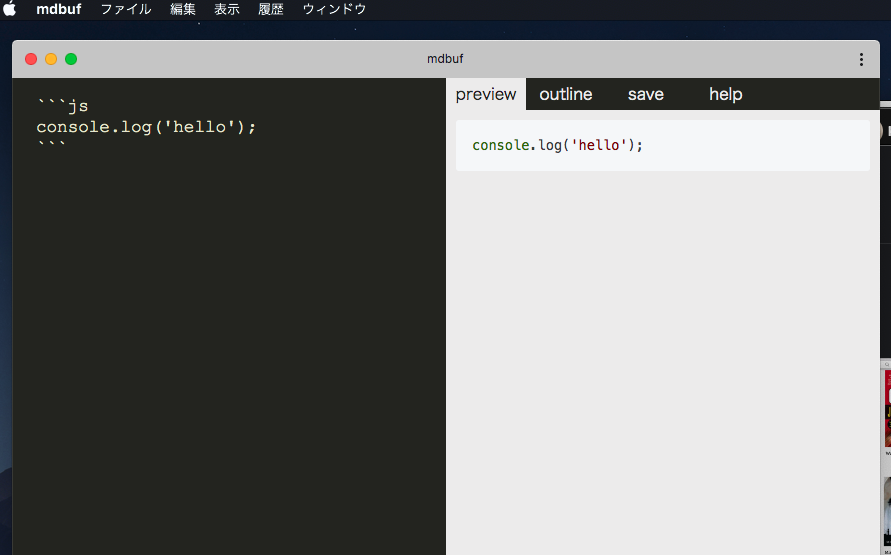
mdbuf について
サンプルで紹介しましたが、これは僕が作ってる markdown のプレビューツール です。
amachang さんや結城浩先生へのインタビュー、その他このブログの記事、各種書籍への原稿も全部これで書いています。
mdbuf v1.0.0: 最高の Mardkown Preview を目指して - mizchi's blog
この時点からさらに自分で使い込みながら機能を足したので、Desktop PWA ついでに紹介。
アウトライン機能
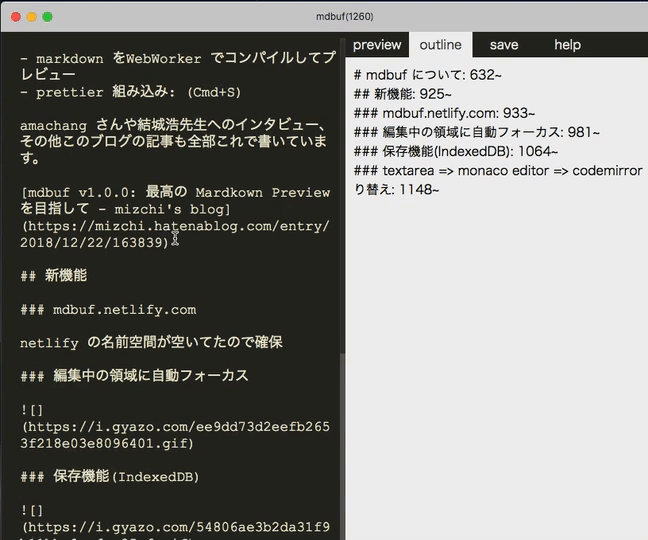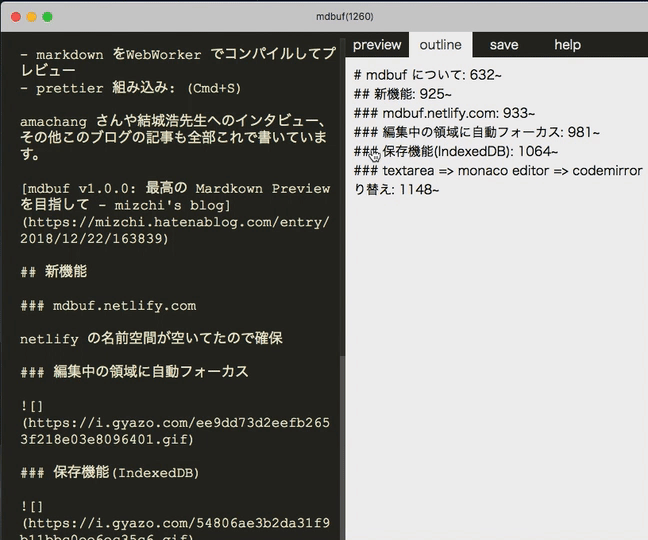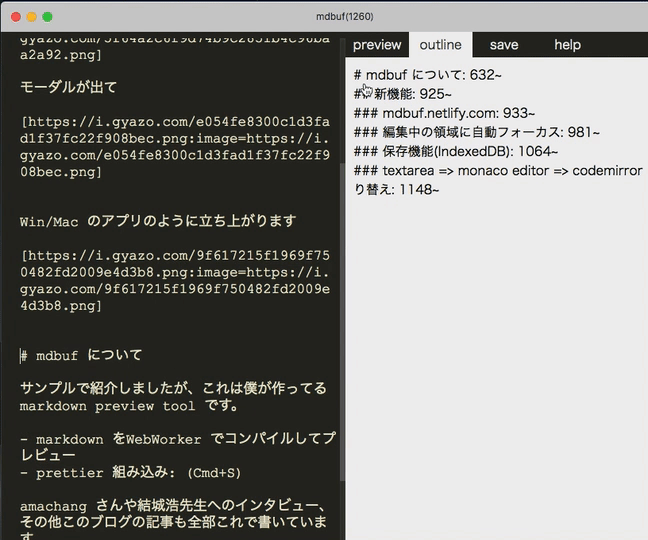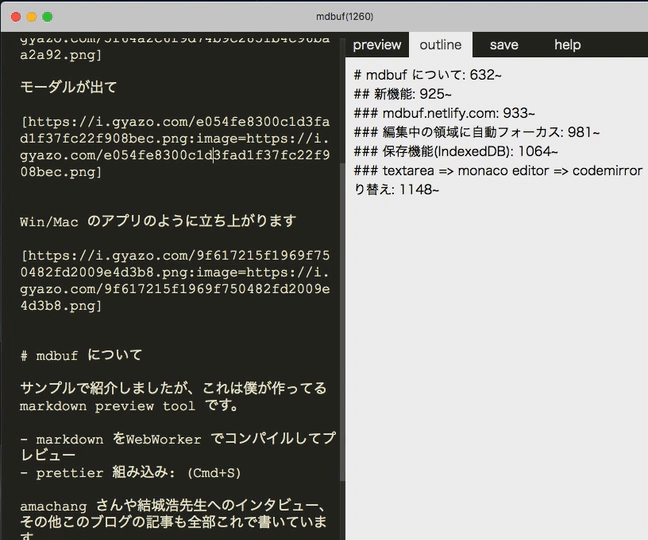
ヘッダの位置にジャンプします。
prettier の整形
Cmd+S (Ctrl+S)で prettier で markdown を整形します。
バックグラウンドのコンパイル
WebWorker でコンパイルしているので、入力中のラグ(layout junk) が非常に発生しづらいです。普通に実装する markdown コンパイルはCPUを専有しがちなので、効果が大きいです。
編集中の領域に自動フォーカス
編集に対応するプレビュー側をハイライトします。
保存機能(IndexedDB)
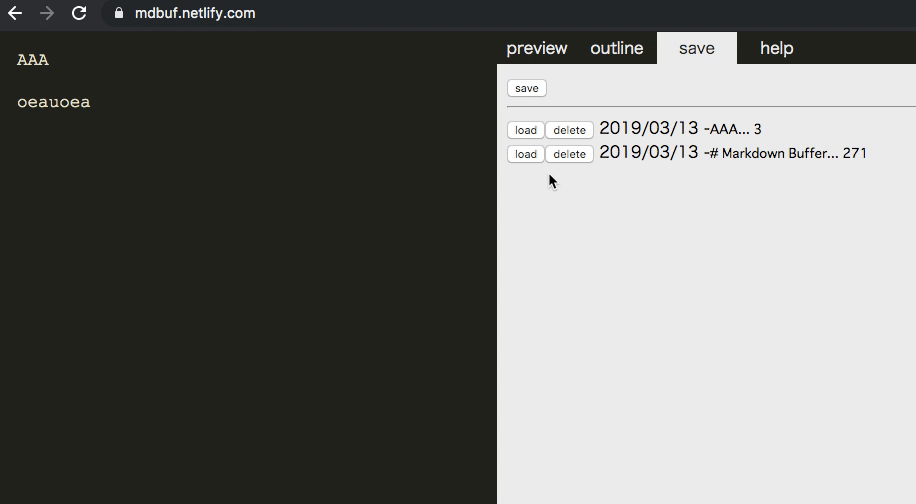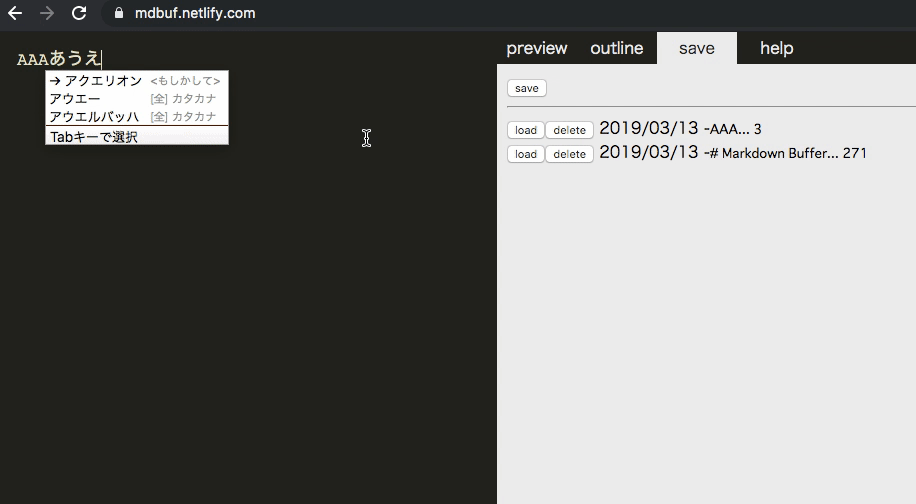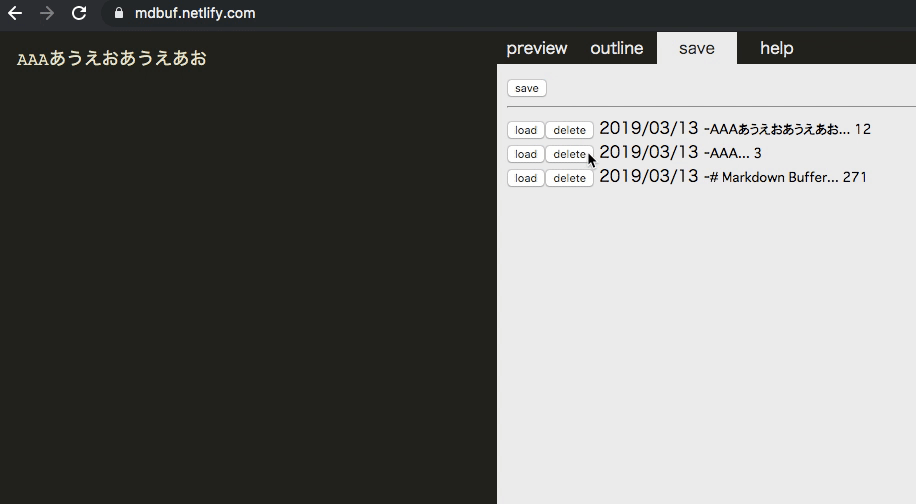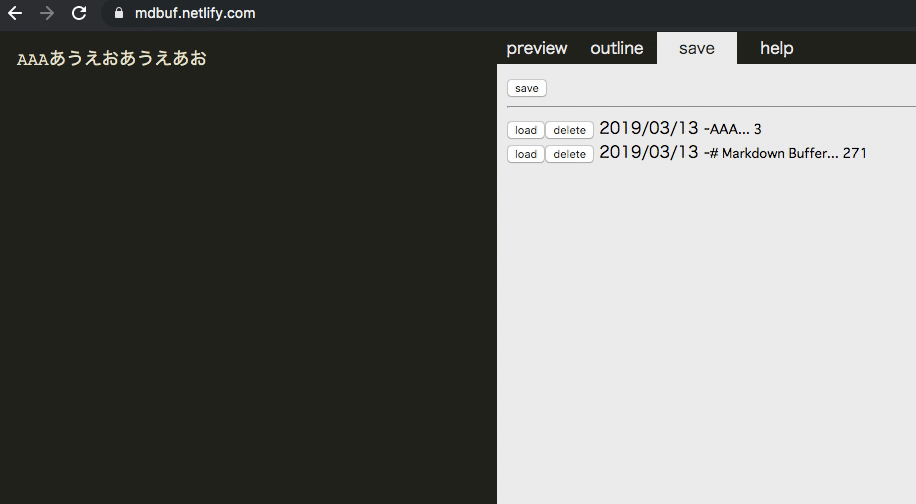
保存します。
textarea => monaco editor => codemirror の切り替え
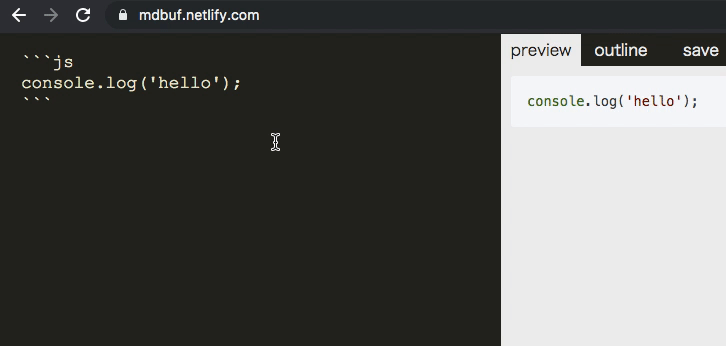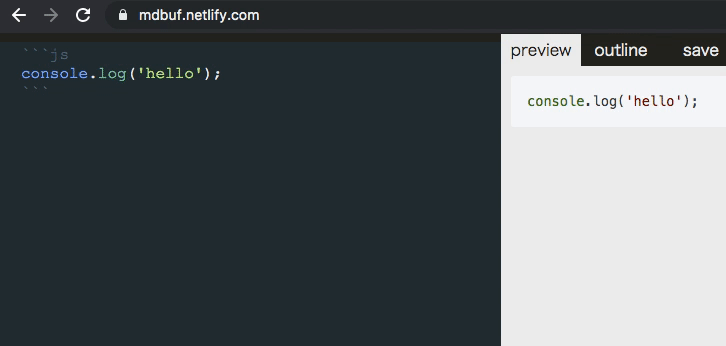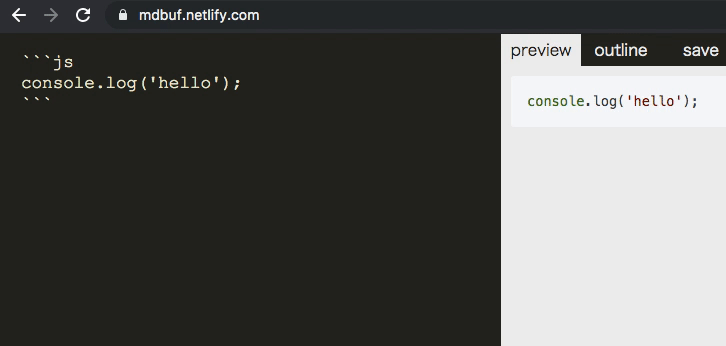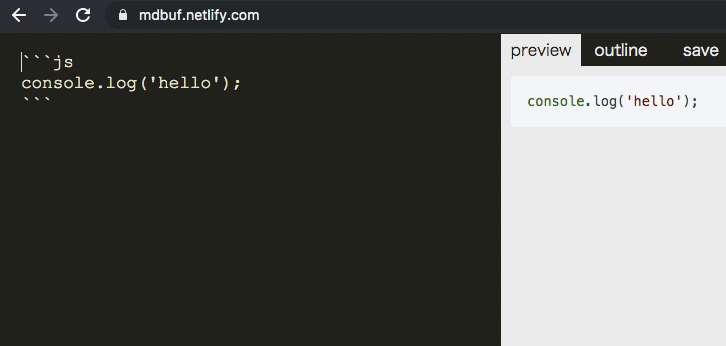
monaco エディタを使えば編集側でコードハイライトできます。
HTMLでコピペできそうでできない要素を作る
歌詞サイト内で湘南乃風の睡蓮花の歌詞がだんだん大きくなっていた「作詞XSSとか楽しすぎるものをみたけど…」 - Togetter
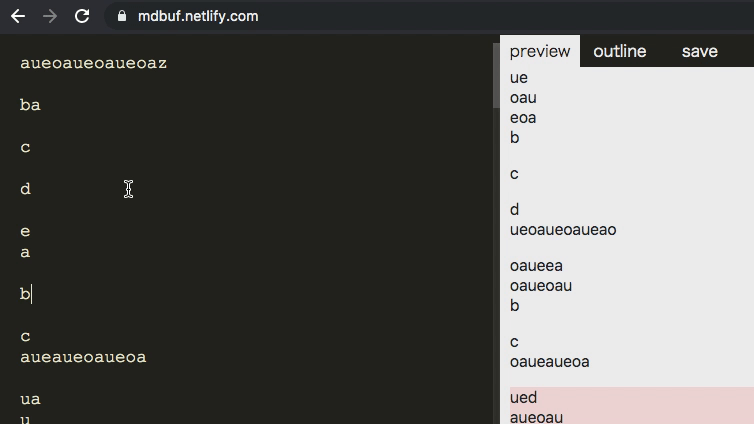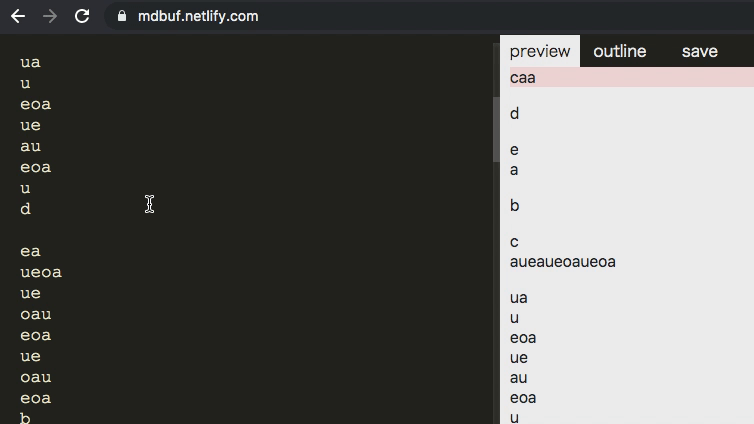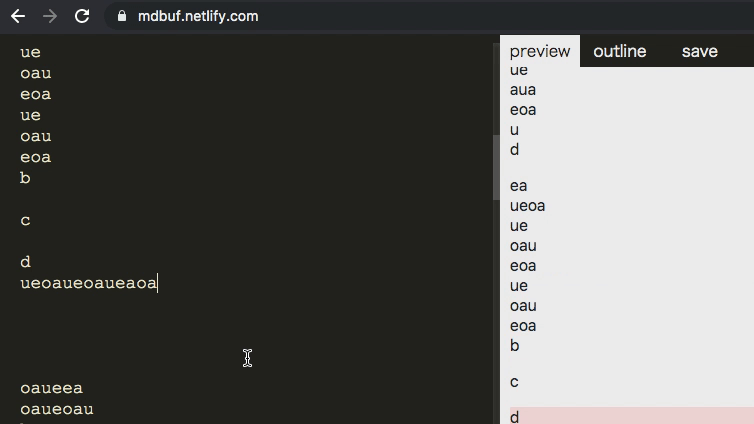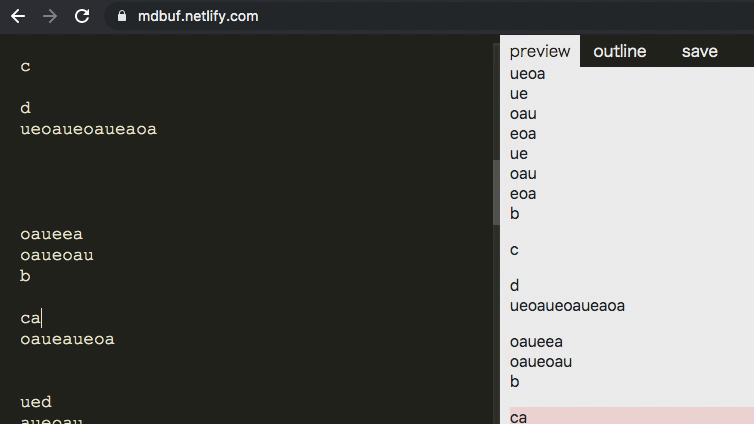
うたまっぷといえばコピペ禁止、コピペ禁止といえば最近こういう嫌がらせを考えていたので、やってみました。
U
O
H
Y
O
-
-
T
N
P
C
-
X
C
-
A
E
I
T
Y
S
O
T
N
T
↑をマウスで選択してコピペしてみてください。うまく範囲選択できないし、できたとしても無意味な文字列になります
仕組み
- テキストをランダムに並び替える
- ランダムに並び替えた文字を, 元の位置に来るように flex の order 属性を指定
フレックスアイテムの並べ替え - CSS: カスケーディングスタイルシート | MDN
コード
React でさっくり書いた
function Text() { const text = "YOU-CANNOT-COPY-THIS-TEXT"; const chars = text.split(""); const textOrders = chars.map(_ => Math.floor(Math.random() * 1000)); const textOrdersSorted = textOrders.slice().sort(); const idxMap = textOrdersSorted.map(v => { return textOrders.findIndex(n => n === v); }); const chars = idxMap.map((to, original) => { return <div style={{ order: to }}>{chars[to]}</div>; }); return ( <> <div> <div style={{ display: "flex", flexDirection: "row" }}>{chars}</div> </div> </> ); } const el = document.querySelector(".root"); ReactDOM.render(<Text />, el);
実行環境
だるくてマルチバイト対応してないので、コードポイントで分割してください。
謝罪文などでこれが来たらいい感じに読者の反感を買えると思います。 悪用禁止!!!!!!!!!!!!!!!
SPA が、ウェブ開発のベストプラクティスになる時代
最近のフロントエンドに関するお気持ち。正直まとまってはない。
最近、こんな感じのツイートや記事が増えた。
シングルページアプリケーション (以下SPA) の台頭により、私の観測範囲ではモダンな Web サイトは SPA で作られるようになった。サーバーサイドは JSON を返す API サーバーとなり、DB やバックエンドシステムのプロキシのような存在になりつつある。 私はサーバーサイドエンジニアとしてキャリアを積んできた。SPA が流行りだした頃、いずれサーバーサイドエンジニアは不要になって自分のキャリアを考え直さなくてはいけない時期がくるのではないかと戦々恐々としていた。
自分も元々、SPA を他サイトとの「差別化技術」と定義していた。ブラウザのタブページのライフサイクルにおいて、初期化プロセスを一回にまとめてシームレスな遷移を実現する技術。たとえばゲームだったり、Electron 環境でネイティブに負けないリッチな UI を提供するためのもの。
しかし、最近ではその潮目が変わってきている、と強く感じる。具体的には、SPA 技術は「すべてのウェブ開発におけるベストプラクティス」になってきたと感じる。
Node.js が Rails に「勝てなかった」理由
元々 Node.js が c10k 問題へのソリューションを謳って登場したのを覚えてる人は、どれだけいるだろうか。その時は他 WAF への Altenative であることが強く打ち出されていた。
それから数年経って、結論から言ってしまえば、Node.js は Rails に勝てなかったのではなく、勝つ必要がなくなった。Node.js は主にフロントエンドツールチェインとして発達し、マイクロサービスにおけるフロントエンド周りを担当する「補助輪」として機能すればよくて、バックエンドに興味を持たなくなった。
現代のストレージは、アプリケーションレイヤーで管理すると言うより、RDS や Aurora, Firebase や Spanner のように、フルマネージドなバックエンドで抽象されるものになった。データベースのスケーリング技術を知識として持つことは依然として重要だが、以前ほど重要ではなくなった。
現代では、並列実行を管理する主体がプログラミング言語のスケジューラから、前段のロードバランサやコンテナのスケジューラに移ってきた。Node.js の弱点はシングルスレッドのイベントループが process fork に向いておらず、シングルプロセスを酷使するや故に例外復帰が難しいことだったが、むしろ現代のマイクロサービス環境ではコンテナに割り当てられた CPU を使い切ることが重要で、例外復帰は投機的なコンテナ単位で行われるようになった。
結論から言えば、 Rails や Symfony のような一つの言語に依存するフルスタックフレームワークは今世代が終わりで、これからはPaaSやマイクロサービス環境で他と協調することが前提のものに分解されていくだろう。しかしそのための土台になると予想される k8s は、数年前のフロントエンドと同じような「難しい抽象を一番うまい抽象化したやつが勝ち」みたいなOSS乱立期で、やや手を付けづらい。
JS の進化 / 漸進的型付けの時代
JS といえば昔はphpやperlと並んで貧弱な言語の代表格だったが、近年の ES2015 以降の言語仕様の進化は目覚ましい。ランタイムにおいても V8 の JIT は異常な域で、繰り返し実行される処理に関しては、ネイティブから「多少遅い」程度のスピードが出てしまう。
また、今は動的型付に対する反動の時代で、ドキュメンテーションとしての型、ある種の Linter としての型というものが再評価されている。その点で TypeScript は漸進的型付けに必要なものを全部備えていて、現代における動的型付けと型の向き合いに関してはほぼ最強みたいなレベルに達している。
漸進的型付け言語の時代に必要なもの - mizchi's blog
というわけで言語仕様的な貧弱さの問題も解決しつつある。TypeScript の型定義も昔はないのが普通だったが、最近は大方ある、という感じになってきた。
そういえば、 python で pyre-checker や mypy を試してみたが、正直実用に程遠い完成度で、これだったらまだ TypeScript のが開発体験は良いという感想。(ただ js では numpy が現状置き換えられないので機械学習用途に使うのは難しい)
依然として後方互換のためのバッドパーツは残っているものの、ES2015 と TypeScript のプラクティスが普及することで解決される問題だと思っている。
WebAssembly は…、たぶん非常に限られた使い道になりそうな予感がしていて、GC インテグレーションの問題が解決しない限りは C++/Rust 以外でまともなサイズのwasmバイナリが生成できない。ツールチェインは Rust がよく出来るので、しばらくはピンポイントで重い処理を Rust を書く、というのがメインになりそう。
パフォーマンス問題
読み込み問題も、読み込みを lazy に分割する chunk splitting の技術や、precat や lit-html のような軽量 View ライブラリ、vue や angular の静的解析技術によるコード生成サイズの減少で、大きな問題にならなくなってきた。
- https://gist.github.com/Restuta/cda69e50a853aa64912d
- https://github.com/developit/preact
- https://github.com/Polymer/lit-html
一部のフロントエンドは、 HTTP/2 + ESModules 環境でブラウザネイティブの ESM ですべてを解決する夢を見ていたが、現状そのための仕様は頓挫し、Webpack を捨てることは、あと数年は困難になった。
Cache Digest と HTTP2 Server Push の現状 | blog.jxck.io
webpack が置き換えられることはあるかもしれないが、その目的はしばらく死にそうにない。
今後の SSR問題
SSRは高難易度の技術だったが、next.js や nuxt.js の普及、国内においては特に nuxt.js が普及したことで比較的手軽になった。自分は React 派だが、正直 next.js より nuxt のが遥かに良く出来てる。(というか next.js は過剰なミニマリズムの病気に掛かっている気がする…)
ついでにいうと、WebComponents は今の仕様のままだと依然として SSR の問題を抱えていて、shadowRoot 下に生成されるコンテンツをクローリングさせるために SSR が必要になっている。というわけで今後もSSRを避けて通ることができないと予想している。
自分が知る限り、SSR を行わないウェブサイトは、ニュースメディアのような速報性が強いサイトには依然として SSR が必要ではあるが、それ以外では意外とインデックスされるし、そこまで重要ではない。(依然として検索スコアが低いような気はしなくはないが…)
これは自分が知る限り、GoogleBOT によるウェブサイトのクローリングが行われると、JS 実行キューに入り、そこでページが構築されるとインデックスされる、という 挙動にある。JS によるページ構築は即座に行われるのではなく、数時間遅れて実行される。
今後の展開としては、BFFのレイヤーはマイクロサービスのクラスターの一部というより、 CDN Edge 上の Edge Worker に主戦場が移って、キャッシュマネジメントとSSRを同時に担うのではないか、と考えている。
Edge Worker PaaS の fly.io が面白い - mizchi's blog
本質的な作業に集中する、とはなんだろうか
主に非エンジニアのスタートアップ事業者や新規事業者にとって興味があるのは、UI と概念のモデリングとそこから生まれる体験であって、そのインフラストラクチャに対応として構成は「仕方なく」やるものなのは変わっていない。(それこそエンジニアリングといえばそうなのだが…)
なので、UI に興味が集中する。なので、競合に勝つための体験、「SPA」に興味が集中するのは、当然のような気もする。ただ、うまく使いこなせているプレーヤーは少なく、とくにパフォーマンスチューニングは属人化しているのが現状(なので自分のようなフロントエンド専門のフリーランスに需要がある)
あるジャンルが高度化しては PaaS/OSS/Container にラップされる、というのを今後も繰り返すだろうが、フロントエンドがそうならないのは、UI は人間の理不尽な要求に振り回される、という特徴にあるという気がしている。
例えばソーシャルゲームはリッチ化の過程でユーザーの期待値が膨れ上がり、開発費が高騰して参入障壁が跳ね上がっているが、似たような現象はどの分野でも起こる。UI への投資が減ることはないだろう。エンジニアとデザイナと連携する部分で AI による生産性の向上はあるかもしれない。
個人的には e2e が未発達なことに課題を感じている。
おわり。
Edge Worker PaaS の fly.io が面白い
なかなかよいおもちゃを見つけたので、紹介します。
fly.io は CDN Edge Worker で JavaScript に特化した PaaS です。既存のサービスで近いものだと CloudFlare Workers もしくは Lambda@Edge でしょうか。
アカウント登録をして、次のようなコマンドを叩くとエッジで動くアプリケーションを作成することができます。
npm install -g @fly/fly fly login # mkdir my-flyio; cd my-flyio fly new
最小コードはこんな感じ。CloudFlare Workers と同じような ServiceWorker 風と、Google Cloud Function 風の 2 つのパターンでワーカーを定義できます。
// index.js addEventListener('fetch', function (event) { event.respondWith(new Response('Redirecting', { headers: { 'Location': 'https://fly.io/docs/apps/' }, status: 302 } )) })
fly.io のここがいい
フロントエンドの最適化の行き着く先の解の一つ、それは「CDN Edge で HTML をキャッシュして返却する」というものです。そして、ある程度動的な JS をユースケースに応じて返却したい場合、 Edge で SSR を行って、一度実行した HTML はキャッシュする、という戦略が有効です。
JS の SSR は、残念ながら今後も必要な技術だと想定されています。しかし、コンテナ技術の発展で、Node の運用の敷居は前より下がりましたが、それでも Node を運用するのを躊躇するエンジニアの方も多いでしょう。
SSR や HTML Cache に対するこれらの懸念を、Edge Worker はまとめて払拭できます。
- 必然的にPaaS なのでフルマネージド
- レスポンス最適化のために Edge Cache で HTML を返せる
- SSR は複雑な処理なので、ほぼフルスペックの Node がいる必要がある
また、SSR / BFF 特有の事情として、次のような要求があります。
- HTML をキャッシュする場合、セッション情報に触れないほうが安全に SSR できる
- SSR の主な需要は大雑把なファーストビューの最適化と、 GoogleBOT 向けの情報を構築することなので、セッションに触れる必要はない
- 起動後にリバースプロキシとして動いて API オーケストレーションを行う
イニシャルビュー最適化で、すべてのリクエストに対してセッション情報付きで SSR するのを要求する人もいますが、運用事故を避けたり、キャッシュ最適化やパフォーマンスチューンまで考えると、この辺が現実的な落としどころだと思います。
つまりは BFF (Backend for Frontend) と呼ばれていた層の一部を地理的に最適化される Edge Location に持ってくることができます。
そして、キャッシュを扱う以上、それなりに KVS を扱いたいわけで、他のサービスではなく fly.io が優れてるのは、この辺のために便利なパーツが一通り揃っていることです。
@fly/cache: リージョン単位の揮発する KVS@fly/cache/global: 永続化されるグローバルな KVS@fly/db: 永続化されたグローバルな簡易ストレージ(Mongo 風?)@fly/static: 簡易アセットサーバー@fly/fetch/mount簡易ルーター@fly/fetch/proxy簡易リバースプロキシ- varnish surrogate key のような、タグによる Cache Invalidation
varnish surrogate key による Cache Invalidation が個人的に一番欲しかったやつで、現状他の CDN だと fastly ぐらいしかこの機能を持っていませんでした。
https://book.varnish-software.com/4.0/chapters/Cache_Invalidation.html
各種ストレージを使ってみた感じ、それぞれは本格的なものではないのですが、アプリケーションサーバーへ到達する前の エッジロケーションにこれがある、ということが大事で、とくに各種キャッシュと簡易アセットサーバー、簡易ルータがあるので、頑張れば Edge で完結するアプリケーション層として動くことすら可能です。
作ってみた
というわけで、簡単な掲示板アプリを作ってみました。各ページはその Edge ではじめてときだけ SSR され、それ以降はキャッシュされた HTML を返却します。初期化以降は CSR で動きます。
https://grave-crowd-822.edgeapp.net
ソースはここ
https://github.com/mizchi/flyio-playground/tree/master/examples/react-ssr
主に React + react-router + styled-components での SSR と、 fly/db に書き込みの内容を永続化して、 fly/cache で SSR 済み HTML をキャッシュしています。next.js などは使わず手作業で無理矢理 isomorphic にしてるので、コードの見通しは悪いです。あとでどうにかする…
作ってみた感想
- node エンジニアなら特に迷うところサッと作れる
- ローカルでほぼサーバーと同等のものが動くので開発が楽 (lambda/cloud function はここが微妙)
- GitHubにソースが公開されてるので最悪これを自分でホスティングすればいいという安心感がある
- express (node http) 互換ではなく、コールバックが
(req, res) => {}ではなく、(req) => new Response(...)みたいな形式 - API ドキュメントがまだまだふわっとしている
- 独自の v8 でビルドされていて、微妙に実装されてないものがある (crypto 周りで動かないモジュールがあった)
fly/dbは、本当にただのおもちゃなので、信用しないほうがいい… (query や scan 相当のものもないし、列挙も出来ない…)- 本番環境での fly/cache/global への書き込みはそれなりに遅い
複雑なストレージを持つようなものではないので、これ一つで完結する、というものではありません。
参考になるリソース
- 公式 API ドキュメント https://fly.io/docs/apps/api/index.html
- GitHub の Examples https://github.com/superfly/fly/tree/master/examples
examples 眺めながら、公式ドキュメントを読みつつ、わからなかったら GitHub で実装を読む、という感じでだいたいやりたいことをやれました。
料金
- $25 の無料枠
- 有料の場合、最低月 $10 から
超大規模想定で適当に試算してみても $100 超えるのは難しそう
で、本格的に使っていいの?
ぶっちゃけリリース直後なので、なんとも言えません。人柱募集したいところ。
とりあえずは、Edge Worker 使った際のアーキテクチャを考察するための実験場として使うのがいいんじゃないでしょうか。ユーザーが増えて、実質 SLA どのぐらいか判明したら、プロダクションに突っ込むかどうか考えれば良さそう。
cloudflare も Edge Worker というよりは Serverless として Edge Worker 市場に参入するぞ!みたいなことを言い出してるので、こっちも注視したいです。
Node.js エンジニアの活路としての Edge Side
前々から思っていたこととして、フロントエンドとサーバーサイドの間に、 エッジサイドのエンジニアという職域がうまれるんじゃないかと想像しています。先に述べたように API オーケストレーション+SSR を行う Node BFF がここに位置するのではないか、と思っています。
日本においては node.js エンジニアは(SFなどの海外と比べて)あまりサーバーサイドでシェアを取れませんでしたが、まともな ORM がない Node 一本で行くのは僕もちょっと厳しいと思っていて、Node が本当に生きるのは、ブラウザと緊密に連携する前段の、Edge Side なんじゃないかと考えています。
Edge Workers は単なるパフォーマンス要件を満たす選択だけではなく、BFF ベストプラクティスとしての活用があると思っています。SPA を何年も作ってきましたが SPA をフルに運用するには、やはりフロントエンドエンジニアが握る BFF が不可欠だという気持ちがあります。
という感じでみなさんも fly.io で遊んでみてはいかがでしょうか。
ちょっと前に Edge ヘヴィーなフロントエンドのアーキテクチャの考察をしたので、こちらもどうぞ
Kaggle Titanic やってみた感想
データサイエンスの一連の流れってどんな感じなんだろう?と体験して見るために、Kaggleのチュートリアルをやってみた。
https://www.kaggle.com/c/titanic
Kaggle Titanic は、Kaggle のチュートリアルでよく使われる題材。タイタニック号の乗客名簿と、生存できたかを含むデータを与えられ、予測モデルを作成し、その精度を競う。
データをダウンロードする
- https://www.kaggle.com でユーザー登録をする。
https://www.kaggle.com/<username>/accountにアクセスし API => Create New API Token から kaggle.json をダウンロード- ダウンロードしたアクセストークンを ~/.kaggle/kaggle.json に置く
以下 pipenv を使った例
$ pipenv install kaggle $ kaggle competitions download -c titanic
これで train.csv と test.csv のデータが手に入る。test.csv は解答用で、生存できたか(Survived)のデータは含まれない。
大雑把な流れ
- 欠損値の処理(今回は単に捨てた)
- 値の正規化(年齢など)
- train.csv のうち 80% を訓練用、20% をテスト用データとして分割
- 訓練モデルを作成
- 訓練モデルにテストデータを入力し、精度を測定
今回は kaggle への提出は行っていない。
keras によるモデル作成
https://github.com/linxinzhe/tensorflow-titanic/blob/master/keras_titanic.py を参考に、理解するためにリファクタしてみた。
from keras.optimizers import SGD, Adam from keras.layers import Dense, Activation from keras.models import Sequential from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import LabelEncoder import numpy as np import pandas as pd def normalize_data(data): not_concerned_columns = ["PassengerId", "Name", "Ticket", "Fare", "Cabin", "Embarked"] data = data.drop(not_concerned_columns, axis=1) data = data.dropna() # normalize dummy_columns = ["Pclass"] for column in dummy_columns: data = pd.concat([data, pd.get_dummies( data[column], prefix=column)], axis=1) data = data.drop(column, axis=1) # normalize Label:Sex to int le = LabelEncoder() le.fit(["male", "female"]) data["Sex"] = le.transform(data["Sex"]) # normalize Age ss = StandardScaler() data["Age"] = ss.fit_transform(data["Age"].values.reshape(-1, 1)) return data def split_train_and_test(data, rate=0.8): data_y = data["Survived"] data_x = data.drop(["Survived"], axis=1) train_valid_split_idx = int(len(data_x) * rate) train_x = data_x[:train_valid_split_idx] train_y = data_y[:train_valid_split_idx] valid_test_split_idx = (len(data_x) - train_valid_split_idx) // 2 test_x = data_x[train_valid_split_idx + valid_test_split_idx:] test_y = data_y[train_valid_split_idx + valid_test_split_idx:] return train_x.values, train_y.values.reshape(-1, 1), test_x.values, test_y.values.reshape(-1, 1) def build_model(input_dim): model = Sequential() model.add(Dense(20, input_dim=input_dim)) model.add(Activation('relu')) model.add(Dense(1, input_dim=20)) model.add(Activation('sigmoid')) model.compile(optimizer=SGD(lr=0.01), loss='binary_crossentropy', metrics=['accuracy']) return model # load data train_data = pd.read_csv("data/train.csv") normalized_data = normalize_data(train_data) train_x, train_y, test_x, test_y = split_train_and_test(normalized_data, 0.8) model = build_model(train_x.shape[1]) # train model.fit(train_x, train_y, nb_epoch=120, batch_size=16) # test [loss, accuracy] = model.evaluate(test_x, test_y) print("loss:{0} -- accuracy:{1}".format(loss, accuracy))
だいたい 80~86%ぐらいの予測率だった。他のチュートリアルを見てもそのぐらいに収束するっぽい。 competition で100点だしてる人たちは、答えをなんやかんややってチートしてそう。
感想
- あんまり綺麗なコード例が見つからない。今回の題材は、チュートリアルなのに、コードを綺麗に見せようという努力がなされたものを見かけなくてイライラした。
- jupyter notebook でやる人が多いのか、数行のスニペット単位で整形することが多く、プログラマ的なモジュール分割ではない、という印象を受けた
- 卒論でR触ってたのでpandas のデータフレームなんとなくわかったが、各種utility が覚えゲーっぽい
- 今回は単に欠損値を捨てたが、中間値で埋めたり、それ自体に予測モデルを作って埋める人が見受けられた。中間値それ自体がバイアスになったり、あるいは欠損値があることそのものがある種の特徴量になってる場合、どう扱うべきか、コンテキストごとに迷いそう
- 出先でやっていたが、バッテリ消費が激しい
- 一応、このデータでは「女・子供は助かる可能性が高い」というのは知っていたのだが、ディープラーニングを使うとその事実に気づくことなくモデルができてしまうので、ドメイン的な学び甲斐がなかった。NNのバイアスから結果に響かない特徴量を検出して捨てる、みたいな手法はありそうなので調べる
実践: React Hooks
hooks が発表されてから趣味でも現場でもずっと hooks を使っています。おかげでだいぶこなれてきて、だいたいなんのライフサイクルでも表現できるようになってきました。
最初は単に useState が state を、 useEffect が componentDidMount/componentDidUpdate を置き換えるもの、と説明を済ますつもりでしたが、 useEffect についてはライフサイクルのモデルがぜんぜん違うので、別の説明をする必要があるように感じていました。
で、その結果 React Hooks を理解するには、関数のメモ化を理解するのが最も簡単だと思ったので、その説明をしつつ、イディオムを解説していこうと思います。
最初に: React Hooks は何であり、何ではないか
関数コンポーネントが状態を持てるようにするもので、関数のメモ化のテクニックを多用します。
redux を置き換えるものではない。が… Redux の機能を一部吸収しています(useReducer)。後述する Context と組み合わせることで、middleware なし Redux が簡単に実現できます。
直接的には recompose や HOC といったテクニックを置き換えるものです。
メモ化されたライフサイクル
(メモ化関数についての基本的な説明をするので、わかってる人は読み飛ばしてください)
const fib = n => n < 2 ? n : fib(n - 1) + fib (n - 2); fib(10) // 55
この fib(10) は、計算の定義自体は簡単ですが、実際には何度も同じ値への計算をすることになります。 これを効率よく計算するため、計算済みの値は保存してしまうこととしましょう。
この fib 関数をメモ化するとこんな風になります。
const memo = [0, 1]; // js の配列のインデックス外へのアクセスの雑な挙動を利用 const fib = n => { if (memo[n] != null) return memo[n]; const r = fib(n - 1) + fib (n - 2); return memo[n] = r; }
これで、 fib(n) が計算済みだったら、計算済みの値を返す、という挙動になります。
ちなみに、 lodash の _.memoize を使って const fib = _.memoize(n => n < 2 ? n : fib(n - 1) + fib (n - 2)); でもメモ化できます。
React Hooks でのメモ化
React Hooks を活用するには、このメモ化の仕組みを理解しておく必要があります。
React Hooks の、特に useEffect と useCallback の第二引数は、このメモ化の理解を必要とします。
function Foo({x}) { useEffect(() => console.log('x changed'), [x]); return <div>{x}</div> }
これは Foo への props x が書き換わるごとに、useEffect が実行されます。 useEffect(fn, memoizedKeys) の fn は、 memoizedKeys ごとにメモ化されている、と言えます。ただし、全ての状態をメモ化しているのではなく、直前の状態だけをメモしています。
ここではメモ化のヒントは 配列になっています。一致判定のロジック自体は配列の各要素の shallow equal、雑に言ってしまうと newKeys.every((k, i) => k === oldKeys[i]) です。
差分検知に失敗するケース
useCallback は memoizedKeys でメモ化された関数を返却します。もし、 memoizedKeys が一致する場合、新しい関数は生成されません。前のステップで生成された関数をそのまま返却します。
x+y が表示され、クリックすると、x+y を console.log する、というコンポーネントで考えてみましょう。
function Sum({x, y}) { const onClick = useCallback(() => console.log('x,y changed', x + y), [x]); return <div onClick={onClick}>{x + y}</div> }
このとき、新しい関数が生成されるのは、 x が変更されるときだけなので、y の更新には反応しません。なので、y だけ更新した際は、表示は更新されても、新しい x と 古い y を足した値を console.log することでしょう。
正しく両方の値に反応したい場合、次のように [x, y] と memoizedKeys を与える必要があるわけですね。
function Sum({x, y}) { const onClick = useCallback(() => console.log('x,y changed', x + y), [x, y]); return <div onClick={onClick}>{x + y}</div> }
より一般化すると、「関数クロージャの中で参照する要素はすべて memoizedKeys に列挙する」というベストプラクティスになると思います。
ちょっとむずかしいですが、総じて、差分アルゴリズムに由来する React らしい、一貫した副作用の抽象化と言えるでしょう。
実行コンテキストの仕組み
見た目上は魔法のように見える Hooks の記法ですが、単に副作用が外出しされているだけです。最初は algeblaic effects が云々みたいな話がありましたが、その話は忘れてください。
中で何が起こっているかは、すごく雑な疑似コードを書くと、たぶんこんな感じだと思います。
// 実行コンテキスト const hooksMap = {} // ReactDOM.render の中の差分更新のどこか const hooks = hooksMap[oldElement.id] || [] const newElement = updateElement(oldElement, virtualElement, hooks); hooksMap[newElement.id] = newElement.hooks;
hooks に実行インスタンスを引っ掛けてコンテキストを生成しているだけです。
より詳しい実装を知りたければ、こちらの翻訳記事を参照してください
(翻訳) React Hooks は魔法ではなく、ただの配列だ
イディオム
componentDidMount/componentWillUnmount 相当
import React, { useEffect } from 'react' function Foo() { useEffect(() => { console.log('mounted') return () => { console.log('unmount') } }, []) return <></> }
state を持つ
import React, { useState } from 'react' function Foo() { const [state, setState] = useState([]) return ( <> {state.map(i => <div key={i}>i</div>)} <button onClick={ ()=> setState([...state, Math.random().toString()]) }> add </button> </> ) }
ref を使って DOM を触る。(textarea にフォーカスする例) DOMへ起きた副作用を検知する場合は useEffect ではなく useLayoutEffect になります。
import React, { useState } from 'react' function Foo() { const textareaRef = useRef(null); useLayoutEffect(() => { if (textareaRef.current) { textareaRef.current.focus() } }, []) return <textarea ref={textareaRef}/> }
外部の副作用を監視して、プログレスバーを進める、みたいな例
import React, { useState, useEffect } from 'react' function Foo() { const [step, setStep] = useState(0); useEffect(() => { // 何か外部の副作用 const unsubscribe = resouce.subscribe(() => { setStep(step + 1); }); return () => unsubscribe() }, [step]) return <></> }
useReducer + context = redux like
useReducer は react で公式に reducer の仕組みが取り込まれたものです。これは単に、state の reducer 版イディオムでしかありません。
これに、親子の間で暗黙に値を受け渡す Context API と、useContext の hooks を使うと、次のように redux 風の flux が再現できます。
import React, { useReducer, useContext, Dispatch, ReactElement } from "react"; import ReactDOM from "react-dom"; type CounterState = { count: number; }; const initialState: CounterState = { count: 0 }; function reducer(state: CounterState, action: any) { switch (action.type) { case "reset": { return initialState; } case "increment": { return { count: state.count + 1 }; } case "decrement": { return { count: state.count - 1 }; } default: { return state; } } } // Container const CounterContext = React.createContext<CounterState>(null as any); const DispatchContext = React.createContext<Dispatch<any>>(null as any); function App({ initialCount }: { initialCount: number }) { const [state, dispatch] = useReducer(reducer, { count: initialCount }); return ( <CounterContext.Provider value={state}> <DispatchContext.Provider value={dispatch}> <Counter /> </DispatchContext.Provider> </CounterContext.Provider> ); } // Connected component function Counter() { const state = useContext(CounterContext); const dispatch = useContext(DispatchContext); return ( <div> Count: {state.count} <button onClick={() => dispatch({ type: "reset" })}>Reset</button> <button onClick={() => dispatch({ type: "increment" })}>+</button> <button onClick={() => dispatch({ type: "decrement" })}>-</button> </div> ); } ReactDOM.render(<App initialCount={2} />, document.querySelector(".root"));
ただし、useReducer はだいぶ redux のそれと比べて、store 層が簡略化されています。middleware の仕組みは一切ありません。
reducer 定義自体は、単に (state, action) => state を守っていればいいです。 redux.combineReducers をヘルパとして使ってもいいですし、redux で使っていた reudcer をそのまま置き換えることも可能です。
とりあえず useReducer + Context で作ってみて、複雑な Middleware が必要だったら Redux を使う、という感じでいいんじゃないでしょうか。
どう適応するか
現状、表現力という点で、関数コンポーネントとクラスコンポーネントはほぼ同等です。
class MyComponent extends React.Component といったクラス記法は、おそらく推奨されなくなるのではないでしょうか。消えることはないでしょうが、推奨されない、といった雰囲気です。
React は関数型プログラミングの雰囲気が強いコアチーム、出自(facebook)、コミュニティなので、おそらく今後見かけるコードは hooks がメインになる気がします。
これは勝手な憶測ですが、React は、頭がいいであろう Facebook のエンジニアがメインターゲットなので、頭が良い人しかターゲットにしていない、というのがたぶんあって、僕はそれが好きではあるんですが、 Vue に初心者層をかっさらわれたのはそういう姿勢に問題があったんじゃないか、という気持ちもあります。
何にせよ、シンプルな一貫したアルゴリズムを理解していれば、すべてがうまくいく、という世界観で、自分はそこが気に入っています。