React Hooks での状態管理と副作用の表現
React Hooks は Stateless Functional Component でも setState 的な状態操作や componentDidMount のような操作を可能にするための仕様提案です。
既に開発ブランチに入っていますが、 現時点で公式に採用されたものではないです。リリース時にはAPIが変わる可能性があります。
React のメイン開発者の一人である sebmarkbage の出してる RFC https://github.com/reactjs/rfcs/pull/68
試してみる
react@16.7.0-alpha.0 に既に実装されており、公式のブログでも解説が出ています。
自分は以下のように動作確認をしました。
yarn add react@16.7.0-alpha.0 react-dom@16.7.0-alpha.0 -D
import React from "react"; import ReactDOM from "react-dom"; const useState: <T>( t: T ) => [T, (prev: T | ((t: T) => T)) => void] = (React as any).useState; const useEffect: (f: () => void) => void = (React as any).useEffect; function Example() { const [count, setCount] = useState(0); useEffect(() => { const tid = setInterval(() => { setCount(s => s + 1); }, 1000); return () => { clearInterval(tid); }; }); return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> </div> ); } ReactDOM.render(<Example />, document.querySelector("#root"));
TypeScript で書いていたので、無理矢理、勉強がてら型をつけていて、その定義がこう。
const useState: <T>( t: T ) => [T, (prev: T | ((t: T) => T)) => void] = (React as any).useState; const useEffect: (f: () => void) => void = (React as any).useEffect;
setState
単純な更新部分から見ていきましょう。
function Example() { const [count, setCount] = useState(0); // ... return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> </div> ); }
ボタンをクリックするとカウントが一つ増えます。
挙動を見る限り、setCount が実行されると、この SFC が再実行されています。
内部的な話ですが、今までだと HoC で関数をラップして状態管理を外出しし、その setState としてラップされた SFC を再実行していたのが、HoC の助けを足りずに状態を持てるようになっています。これはライブラリ本体に手を入れないと実現できない挙動です。おそらく、実行コンテキストで登録されたリスナーとインスタンスの関係を結びつけているんでしょう。
uesEffect
useEffect は render とは関係ない副作用を記述するための機能です。
宣言的に開始処理、終了処理が書けます。
例1
setInterval 用のタイマーを登録する例
function Example() { const [count, setCount] = useState(0); useEffect(() => { console.log("start timer"); const tid = setInterval(() => { setCount(s => s + 1); }, 5000); return () => { console.log("stop timer"); clearInterval(tid); }; }); return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> </div> ); }
このコードでは、5秒に1回、値をインクリメントします。
これで気をつけるべきは setCount を呼ぶことで、useEffect の終了処理が呼ばれ、再実行されることでタイマー登録処理が再登録されます。
なので、この Click Me をクリックすると、setCount が呼ばれ、タイマーがリセットされます。なんでもいいから最後に更新されてから5秒後にインクリメント、が再定義されているわけです。
ここまで書いて気付いたんですが、一回実行されるたびに setiInterval は必ず、 clearInterval され、かつ再登録されるので、setTimeout でも全く同じ挙動になりますね。
useEffect(() => {
const tid = setTimeout(() => {
setCount(s => s + 1);
}, 2000);
return () => {
clearTimeout(tid);
};
});
この、「最後に実行されてからの effect だけ意識する」というのは、ちゃんと使う限りは副作用を起こすコードで意識すべきスコープを狭く出来て、とても良さそう。
例2
カウンタが奇数のときだけ useEffect を持つ Foo を表示してみます。
function Foo() { useEffect(() => { console.log("foo start"); return () => { console.log("foo end"); }; }); return <div>foo</div>; } function Example() { const [count, setCount] = useState(0); return ( <div> <p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button> {count % 2 === 1 && <Foo />} </div> ); }
ボタンを何度かクリックしてみたときの Console
foo start foo end foo start foo end foo start foo end
再更新だけではなく、外からアンマウントされる際のデストラクタでもある、という感じですね。 componentWillUnmount のように使うことができるという感じ。
useReducer
setState の reducer 版
型はこんな感じ
const useReducer: <T, A>( reducer: (s: T, a: A) => T, t: T ) => [T, (action: A) => void] = (React as any).useReducer;
コード
type State = { count: number; }; type Action = | { type: "reset"; } | { type: "increment"; } | { type: "decrement"; }; const initialState: State = { count: 0 }; function reducer(state: State, action: Action): State { switch (action.type) { case "reset": return initialState; case "increment": return { count: state.count + 1 }; case "decrement": return { count: state.count - 1 }; } } function Counter() { const [state, dispatch] = useReducer(reducer, initialState); return ( <> Count: {state.count} <button onClick={() => dispatch({ type: "reset" })}>Reset</button> <button onClick={() => dispatch({ type: "increment" })}>+</button> <button onClick={() => dispatch({ type: "decrement" })}>-</button> </> ); } ReactDOM.render(<Counter />, document.querySelector("#root"));
第三引数を渡すと、それを元に初期化する。
const [state, dispatch] = useReducer(
reducer,
initialState,
{type: 'reset', payload: initialCount},
);
これは reducer の function reducer(state = initialState, action) {...} の initialState の部分を外出しできるって感じっぽいですね。
全体的に、initialState を受け付けるが、 state 自体は外部にメモ化されていて状態を持ってる、って感じですかね。個人的には常に initialState を受け付けてるように見えて、あまり直感的ではないような気も…。
他のヘルパ
- useMemo
- useCallback
- useRef
- useImperativeMethods
- useMutationEffect
あとでちゃんと勉強する
感想
ライブラリでは表現できない、React 本体だから実装できる感じの API だと感じます。 class extensds React.Component の API あんまりつかってほしくなくて、SFC で全部が表現できるようにしようってのを感じますね。React コアチームは HOC と redux 嫌いそう。
記述の自由度、奔放さが上がる代償に、行儀が悪いコードも沢山かけてしまうよなーという印象もあります。 メモリリークなく useEffect を正しく使うには RAII ちゃんとやるみたいなのを徹底しないといけないので。
useEffect は宣言的な React から抜け道を用意する感があって、ちょっと怖いですね。
Issue 見る限りは、 hot reload どうすんの?みたいな質問とかがあって、確かに既存のは動かなさそう。
Mac で pyenv / pipenv の環境を作って keras 動かすところまでのメモ
tensorflow.js で遊んでたら keras でモデルを作って import してみましょうみたいな章に差し掛かったので、python の環境構築した。
TensorFlow.js tutorials - import-keras
環境構築
keras ついでに pyre を試してみたいので、 pyre で keras が書ける、というところをゴールにした。
pipenv は ruby の bundler みたいな体験を目指して入れてみた。
ググってみると Mac で Anaconda は地雷みたいな意見が多かったので、とりあえず homebrew から pyenv と pipenv を入れて、pyenv から python を管理することにした。
brew install pyenv brew install pipenv
export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"
自分は POSIX 非互換の fish を使ってるので ~/.config/fish/config.fish に以下を追記
set PATH $HOME/.pyenv/shims $PATH eval (pyenv init - | source)
ここで、 xcode-select --install して、 pyenv install 3.7.0 とすれば python が入るらしいが、自分の環境では次の記事と同じ問題が起きた。
pyenv install 3.6.6 でエラーが発生する。 – digitalnauts – Medium
おそらくだが、自分が homebrow を ~/brew にインストールしている関係で、python-build が期待してる環境変数からずれてしまってそう。
結論から言うと、上記の記事と同じように、色々と環境変数で渡すとビルドが成功した
# python 3.6/3.7 install $ CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" \ LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" \ PYTHON_CONFIGURE_OPTS=--enable-unicode=ucs2 \ pyenv install -v 3.6.6 $ CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" \ LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" \ PYTHON_CONFIGURE_OPTS=--enable-unicode=ucs2 \ pyenv install -v 3.7.0
keras 起動まで
3.6 と 3.7 を入れた理由だが、 python 3.7 で async が予約語になった関係で、 tensorflow のコード中にある async 変数でパースエラーになる。なので python 3.6 を使う必要がある。
Unable to install TensorFlow on Python3.7 with pip · Issue #20444 · tensorflow/tensorflow
$ mkdir try-keras $ cd try-keras $ pipenv --python 3.6 $ pipenv install tensorflow $ pipenv install keras $ pipenv shell $ python --version # => 3.6.6
コードを書く
src/hello-keras.py
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
$ python src/hello-keras.py Using TensorFlow backend. Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz 11493376/11490434 [==============================] - 6s 1us/step
動いた。
pyre-check を動かしてみる
Python 3 系は型の構文が予約されてるが、処理系にバリデータがあるわけではない。
その Type Checker の実装に mypy と pyre がある。 JS の flow と同じ作者の雰囲気を感じるので、今回は pyre を使った。
$ pip3 install pyre-check $ mkdir try-pyre $ cd try-pyre $ pyre init $ mkdir src $ vim src/hello-pyre.py # type your code $ pyre --source-directory src check ƛ Setting up a .pyre_configuration file may reduce overhead. ƛ Found 1 type error! src/test.py:2:4 Incompatible return type [7]: Expected `int` but got `str`.
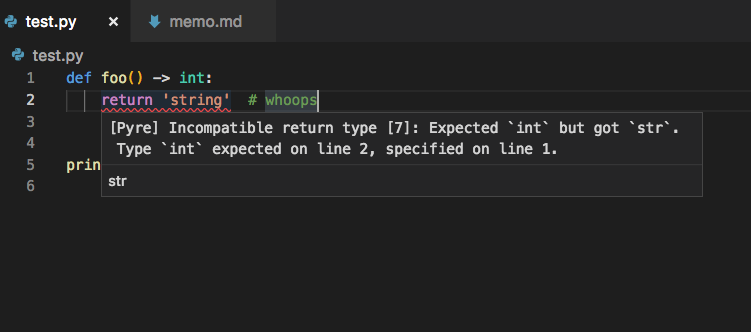
自分で書くコードに型をつけるには便利だが…
keras で使うと import path を知らないと言ってくるのを、だまらせる設定が必要だった。
こうするとさっきのコードに pyre-check が通る。
from keras.datasets import mnist # pyre-ignore (x_train, y_train), (x_test, y_test) = mnist.load_data() # pyre-ignore print(x_train)
結構だるい。mypy は 知らないモジュールの import を無視するオプションがあるらしいが、 pyre にはない。
(facebook はたぶん pytorch 使ってるんだろう…)
環境 & エディタ
vscode で python を開くと vscode が yapf を有効化する?ってきいてきたので、yes にしたら勝手にフォーマットされるようになった。便利
終わり
本記事と関係ないけど最初は Python でプログラミングを覚えたが、就活の頃(2012 年頃)全く python の仕事がなかったのと 2 系と 3 系の移行期で混乱していたので、 Node.js/JavaScript に切り替えた記憶がある。
昔も同じように環境構築で苦しんだ記憶があるが、その体験はあまり変わっていない。
MarkdownBuffer の実行時間の計測とパフォーマンスチューニングの余地
昨日作った mdbuf が 100000文字を超える場合、遅いときいたので、色々試してみた。
手元で18万のテキストを用意して編集してみた。それなりに重いが、それでもIMEを完全にブロックしてしまうほどでもない。とはいえイライラはする。
innerHTML で挿入にかかる時間を計測してみた結果、自分の手元では markdown 10000文字あたり、1.6ms の遅延。というわけで、体験を損ねない限界は 100000文字辺りが限界だと思う。とはいえ自分は最新モデルのMackbook Pro の中位ぐらいのモデルなので、平均的にはその半分の5万文字ぐらいだろうか。
ただ、画像がある場合には入力の度にリクエストが走ってるような気がするので、それのリサイズも合わさって、あまり良くない気がする。あとでアクセスがキャッシュに閉じてるか確認しておく。
細かい工夫として、IMEの変換中はプレビューの更新を止めてる。IME 変換中の不整合な状態を見たい人はいないと思う。日本語の入力はこれでだいぶ体験よくサボれる。
経験上、原稿書いてるときは多くても1万から2万ぐらいで別ファイル(章)に切ってるし、100000字はさすがにサポート外と言ってしまったほうが良さそう。基本的には20000文字ぐらいまでではないか。
でも将来的には大容量テキストをサポートしたいし、そのための実験を色々やった。
機能追加
- textarea 上で Ctrl 押しながらマウスホイールでプレビュー側を更新
- Tab/Shift+Tab でインデント
- プレビューが隠れている場合はレンダリングしない
スクロールシンクを実装しない代わりにマウスホイールで移動できるようにしたらめっちゃ便利でこれでいいじゃんとなった。
作図ツールが欲しくて、mermaid.js の組み込みやってみようとしたら remark-mermaid が fs 使ってて node 環境でしか動かないコードだったので、その部分を剥がして直接使えるか確認しに mermaid の SVG レンダラーのコードを読みにいったら、あまりに汚いコードで使う気が失せた。自分でそれっぽいの書くかも。
大規模な markdown 対応で、アウトラインへのジャンプはほしいかもしれない。そうしたら100000超えた際のサポートにも意義が出てくる。
textlint 組み込みをやろうか迷ったが、何入れても不満でそうで、汎用的なルールが思いつかなかったので後回し。
裏側で複雑な実装が増えてきたので、さっくりReact化しておいた。
実験
innerHTML への代入ではなく、差分レンダリングの仕組みを考えていて、手元で remark-react(preact) => worker-dom => MainThread での MutationRecord 適用というフローを試してみた。worker-dom 側での仮想DOM生成はうまくいったが、逆にMainThread から Worker 側にデータを投げる仕組みが見当たらなくて、無理矢理パッチ当ててみたが、よくわからなかった。もうちょいでできるはずなので、後一日ぐらい調べる。
これがうまくいけば、更新された DOM へのスクロールを作れば、スクロールシンクも実装できる。
React でやってない理由として、仮想DOMは実DOMと色々紐付いているせいで Worker で生成/破棄が出来ない。これが理由で worker-dom と、その上で動くことはわかっている preact で調べていた。MutationRecord に対し react-reconciler で自前 renderer を実装するという手がなくはないが、実装量が半端ないのでやりたくない。
これらがうまく言っても、裏のスレッドを専有してる Markdown のコンパイル時間は何も解決しない。本当に大きなファイルの場合、適当な位置でテキストを分割して8スレッド並列でMapReduceするみたいなことは思いついたが、実装のだるさの割に報われなさそうで、まだやる気があんまない。
Rust で書いて wasm バイナリで高速化するという手もあるが、remark 相当の拡張性、便利さを再現できなさそう。面白そうなテーマではある。
大量のテキストを食っても速い Markdown Editor 作った
もう人生で何個目かわからない markdown エディタ作った。が、今回のは結構気に入っている。
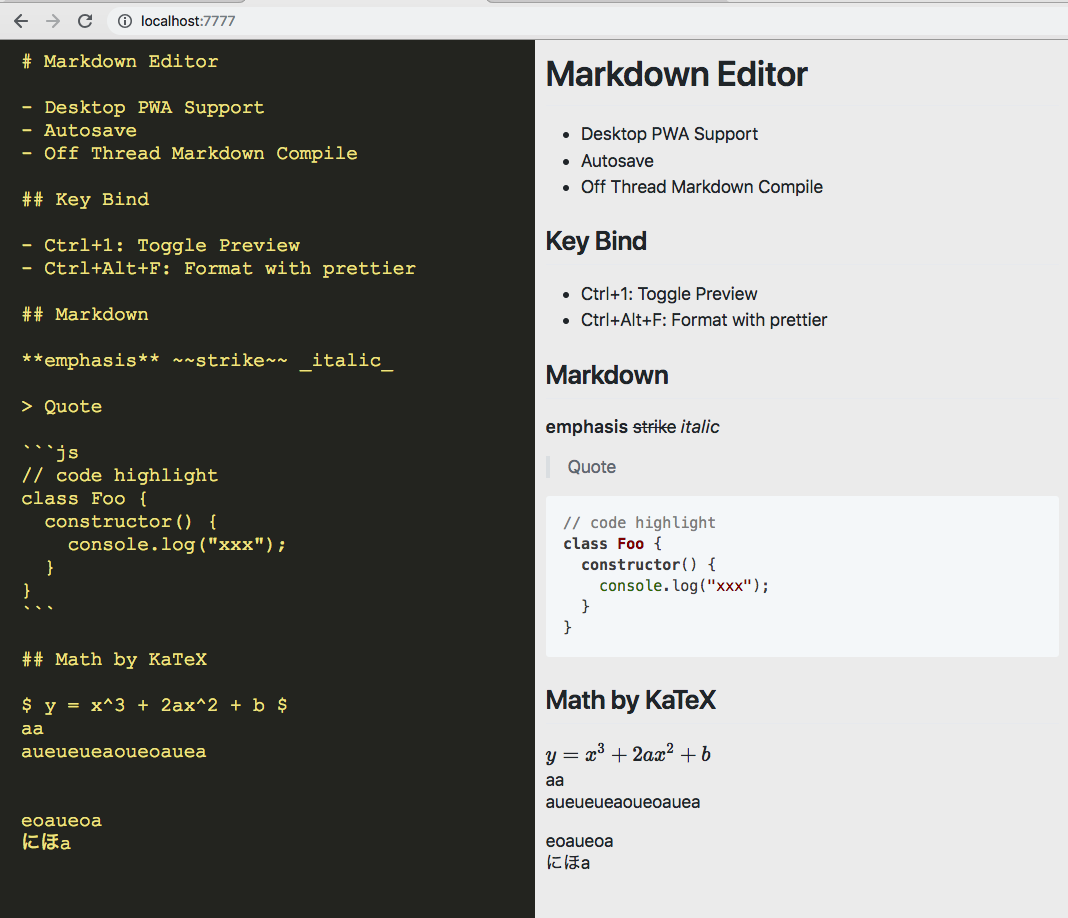
https://markdown-buffer.netlify.com/ で遊べる。
用途としては、GitHub か Qiita か はてなブログかわからないが、なにか書こうと思ったときに、どのサービスも中途半端に重いので、とりあえずのバッファが必要、という感じで作った。なので速度重視。
ブラウザのストレージで永続化してる。オフラインで動く。できるだけエディタとしてはスコープを大きくせず、単に編集バッファ(textarea)でしかない、というのを意識している。
結構頑張って作り込んでしまった https://nedi.app が色々肥大化してしまっていて入力時にラグを感じるので、編集体験を見つめ直す自戒もある。
機能
- 数式対応
- コードハイライト対応
- バックグラウンドで自動保存
- 改行を br に(line-break)
- Desktop PWA 対応 (chrome://flags から有効化)
- Ctrl+Alt+F で Prettier
- Ctrl+1 で プレビューをトグル
- WordCount 機能
スクロールシンクを実装してない。厳密にやろうとすると面倒なので後回し。
off-the-main-thread
メインスレッドのパフォーマンスをかなり意識した。
たとえば、なぜ仮想DOMという概念が俺達の魂を震えさせるのか - Qiitaの markdown、8000字程度を remark でコンパイルするのに、メインスレッドで 23~40ms 掛かる。これは一文字打つたびに、実際にもたつきとして感じられる。
これを WebWorker に逃がすことで、メインスレッドで入力中は全くラグらなくなった。
DevToolsのフレームグラフみても全然負荷掛かってない。
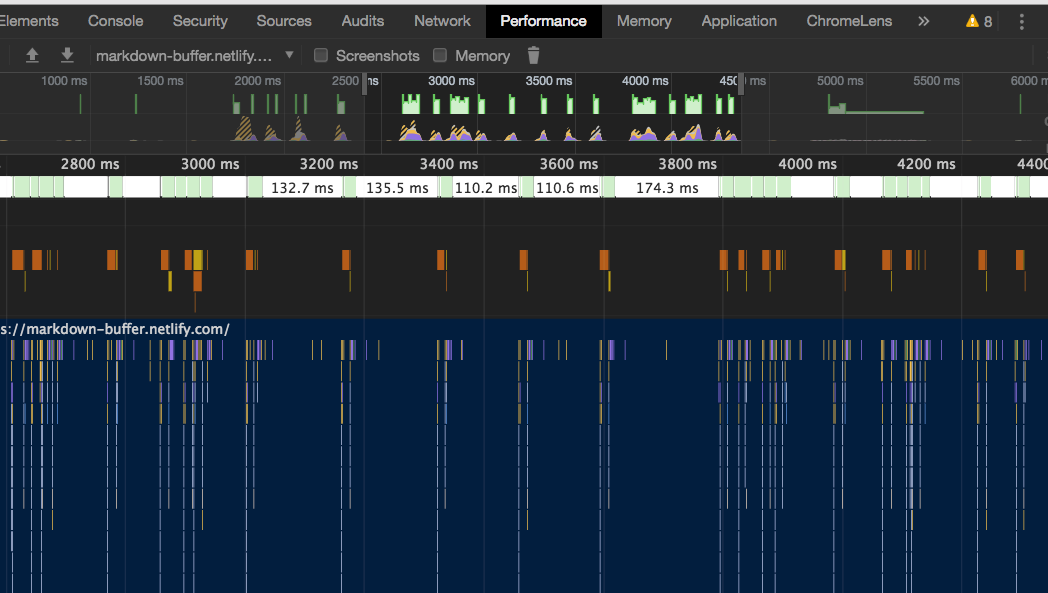
その代り、postMessage が往復する時間で 4ms x 2 ぐらいのプレビューの遅延が発生した。0.5フレームなので人間が意識するのは難しい。
バックグラウンド側のスレッドの初期化がチョット重いのだが、これは prettier/standalone のせいで、ただこいつを入れた結果ブラウザで prettier 使えるようになったので、まあいいかという感じ。もっとグレースフルに初期化する方法もあるが、そこはサボった。
使ったライブラリ
https://github.com/GoogleChromeLabs/comlink を使って postMessage をラップした。とても使いやすかった。
WebWorker 側だと localStorage に触れず、 IndexedDb を使う必要があったので、https://github.com/dfahlander/Dexie.js を使った。
remark の設定
このエディタでの書いたものを、外に持ち出したい場合の remark
import "github-markdown-css/github-markdown.css";
import "katex/dist/katex.min.css";
import "highlight.js/styles/default.css";
import remark from "remark";
import math from "remark-math";
import hljs from "remark-highlight.js";
import breaks from "remark-breaks";
import katex from "remark-html-katex";
import html from "remark-html";
const processor = remark()
.use(breaks)
.use(math)
.use(katex)
.use(hljs)
.use(html);
const html = processor.processSync("# Hello!).toString()
この DOM がすごい2018: worker-dom
おもしろライブラリを見つけて興奮しているので紹介します。
UIスレッド(メインスレッド)からユーザー操作をブロックしてしまうような重い処理を逃がす off-the-main-thread を実践しようとなると、実際に問題になるのは、ほとんどの処理は何らかの形で DOM を参照し、それに連なるものが処理時間の殆どを占めている、ということです。
off-the-main-thread の時代 - mizchi's blog
DOM に触れない WebWorker でビジネスロジックを処理するのは、ある種の健全性(Universal/Isomorphic)を手に入れるための「縛りプレイ」として有用ですが、現状は実用上のメリットが殆どありません。
例えば react / redux の reducer で、ビジネスロジックを worker 側に移して処理できるぐらいアイソモーフィックに(DOMに触れずに/nodeでテストできるように)記述することは可能ですが、 redux の処理がボトルネックになることはほぼなく、基本的にその後のReactの内部的な更新処理がユーザーの処理をロックするのがほとんどです。React/Vueのようなライブラリの処理をWorker側に逃したいと思っても、DOMと密接に絡んでいる以上、現状はその手段がありません。
worker-dom
そんな中、AMP Project から面白いものが出てきました。
ampproject/worker-dom: The same DOM API and Frameworks you know, but in a Web Worker.
WebWorkerでDOMを実行できるようにする、という実装です。
動くのはこんなコード
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1"> <script src="/dist/index.mjs" type="module"></script> </head> <body> <div src="hello-world.js" id="root"> <div class="root"><button>prompt</button></div> </div> <script type="module"> import { upgradeElement } from '/dist/index.mjs'; upgradeElement(document.getElementById('root'), '/dist/worker.mjs'); </script> </body> </html>
ここまでは Main Thread での Worker の起動部分
const root = document.createElement("div"); const btn = document.createElement("button"); const text = document.createTextNode("Insert Hello World!"); root.className = "root"; btn.appendChild(text); root.appendChild(btn); btn.addEventListener("click", () => { const h1 = document.createElement("h1"); h1.textContent = "Hello World!"; document.body.appendChild(h1); }); document.body.appendChild(root);
(APIがなんかダサいですが、アルファ版ということで…)
このJSが worker 側で動いて id="root" の DOM が操作される、ってことですね。
これがなぜ AMP からでてきたかというと、AMPは色々とビジネス的な側面もあってややこしいのですが、基本的にはベストプラクティスの強制によってWebの体験を良くしたい、というのが彼らの発想です。例えばレンダリング最適化の為の CSS インライン化であったり、レンダリングをブロッキングするような JS の禁止だったり…
で、AMP Project は別に好き好んでJSをブロックしている訳ではなく、彼らが嫌っているのは JS によるメインスレッドの専有です。なので Worker で DOM 操作すればいいのでは?という発想の元、 worker で DOM を動かす、というライブラリを試験的に試しているんでしょう。AMPから出てきたといっても、特にAMPでしか使えないというものではないです。(そもそもサブセットなので)
好きなJavaScriptをAMPで実行できるようになるかも。Web Workerで実現か? | 海外SEO情報ブログ
どうやって Worker 上での DOM を実現しているか
というわけでコードを読んできました。
基本的には、 Worker側に実装した MutationObserver をメインスレッドに postMessage して適用する、という感じです。
この記事の前段階として、コードリーディングのメモがあるので置いておきます。 worker-dom-code-reading.md
Worker 側の変更を Main Thread に伝える
- Worker 側に DOM のロジックをまるごと実装している
- Worker 側に実装された MutationObserver で、 MutationRecord を捕まえる (MutationRecord - Web API インターフェイス | MDN)
- MutationRecord を JSON にシリアライズし、postMeassge で MainThread へ送りつける
- MainThread で MutationRecord を復元し、実DOM へ適用操作を行う
JavaScript で MutationObserver 含む DOM API を全部実装してるのが正気ではない感じですが、Googleならではの腕力という感じ…
UI Event を Worker に送る
- Main Thread で発生した event をキャッチして、シリアライズして Worker に送る
- Worker 側で イベントスナーを発火させる
この結果、Worker にまるで DOM があるかのように振る舞わせる事ができます。コード読むとWebWorkerの名前空間に self.document などを露出させていて、JSDOM でテストを書くときなどの雰囲気に近いですね。
つまり、今までこうだったのが
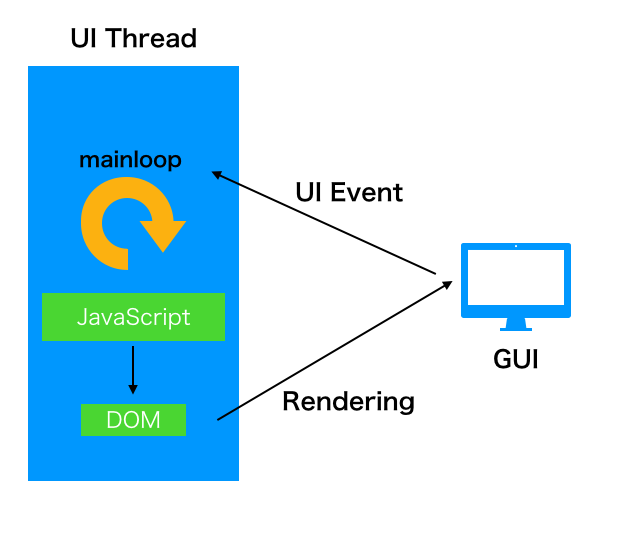
こうなるということです。
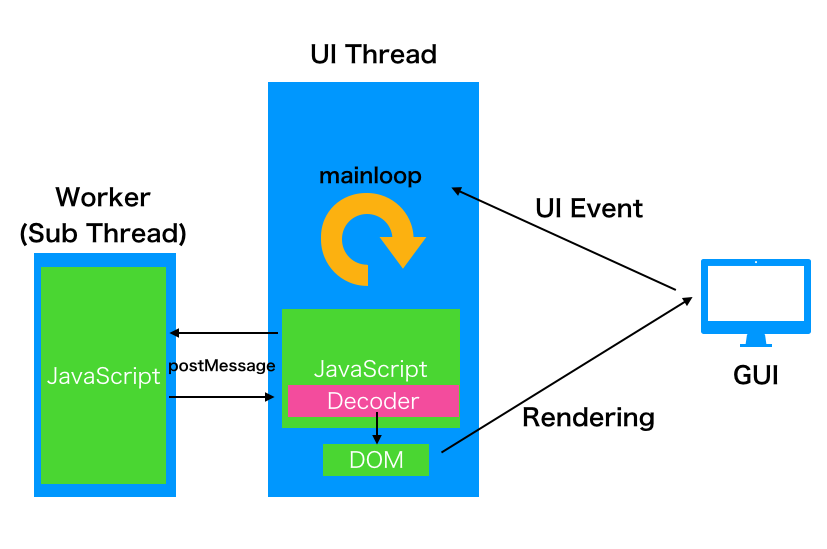
この UI Thread のJavaScript では UI Event を Worker に渡すだけで、Scripting 処理自体は初回にworkerを起動して、あとは postMessage するだけなので、基本的に Worker 側で全てのロジックを捌きます。例えばReact/Vue の仮想DOMの生成/比較のようなボトルネックになってた部分も解決する可能性があります。
demo見る限りは preact の実装があります。コードを読んでいても React を動かすには〜みたいなコメントが散見されるので、意識してるみたいですね https://github.com/ampproject/worker-dom/tree/master/demo/preact-todomvc
この手法の問題
event.preventDefault()のような同期的にイベントバブリングを中断する処理が実現できないwindow.getComputedStyleのように、レンダラから値を取り出すような処理が出来ない(Worker側にレンダラがない為)- postMessage で JSON のシリアライズ/デシリアライズのコストが余分に掛かる
- MutationObserver がJSなので、ネイティブ実装に比べて遅いのではないか(要検証)
preventDefalut の部分は本質的な問題で、web-components でそもそもバブリングしないボタンを作るとか、Facebook の Yoga エンジンみたいなレンダラをWorker側に実装してしまうとか、そういう荒業が思いつかなくはないのと、縛りを受け入れて書くのは不可能ではないのですが、なんとかなってほしい…
展望
見た感じ筋が良さそうに見えます。裏側に偽のDOMを置いて、その差分だけ実体に通知するという発想は仮想DOMと似ていますね。
もしこれが実用可能になったら、既存のJSをそのまま移すという用途ではなく、ライブラリの下回りで使ってユーザーは気付いたら WebWorker 名前空間にいた、という体験になるんじゃないでしょうか。
追って調査して、実用できそうになったらまた報告します。
WebAnimation の為のタイムラインエディタを試作してみた
ペルソナ5みたいな UI 作りたいみたいな話あって、メニュー画面の動きだけでも作れないか、と主要な動線だけ雑にReactでスケッチしてみたが、早々に限界が訪れた。
理由はいろいろあるが、(無限に気合でやれば終わるが) (そもそもどこにゴールに設定するかおいといて…) 細かいタメを作るのにフレーム単位の制御が必要。現代のHTML5には Flash Studio の代替がないという問題があり、本格的じゃなくていいからそれっぽいやつを作れないかと思って、試作してみた。
動画
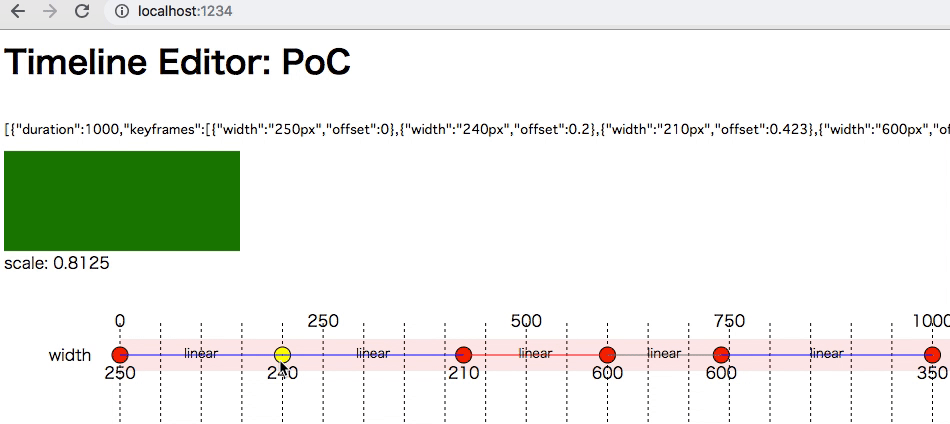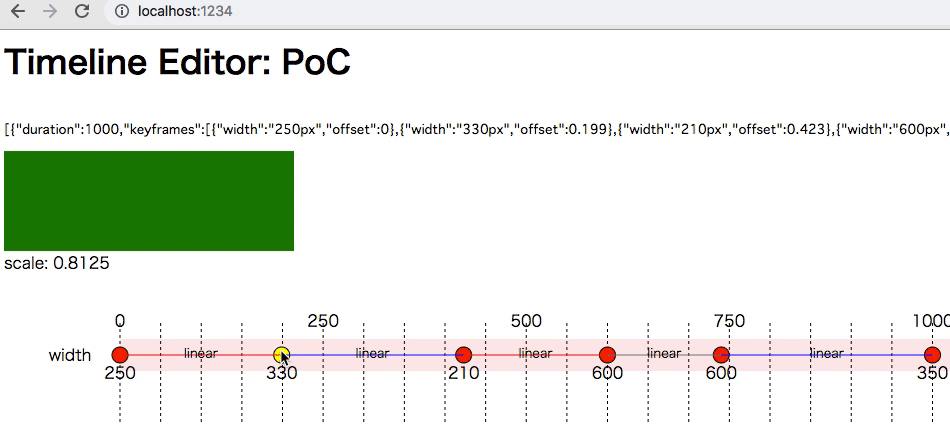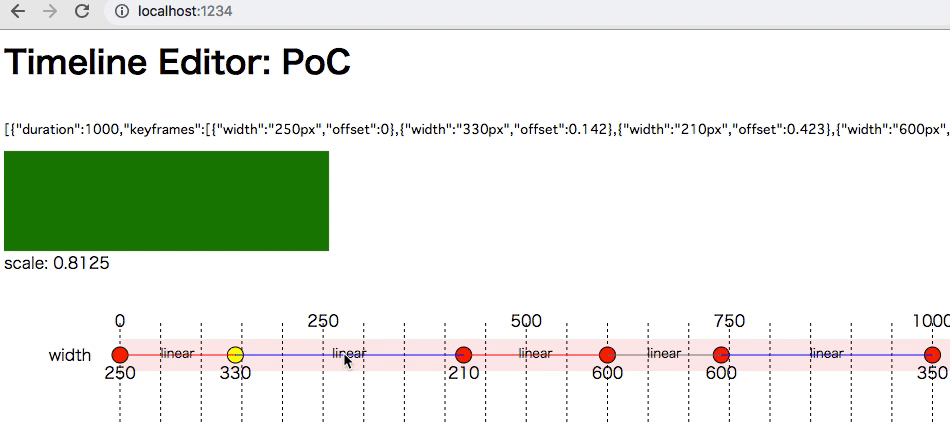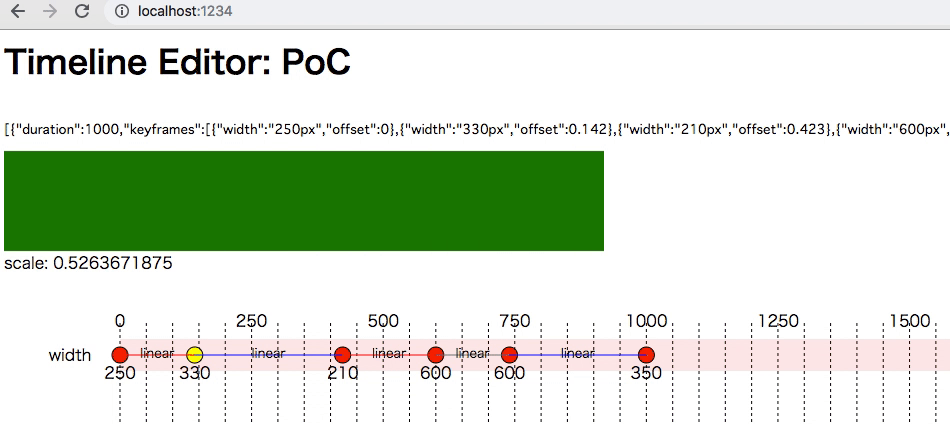
ここで試せる https://5bbe44153813f06f1ff69d0c--timeline-editor.netlify.com
- クリックでアンカーを撃てる
- アンカーをカーソルキーで値とタイミングを調整できる
- width のみ
- easing も linear のみ
GitHub のコード (きたない)
中身
Web Animation に食わせるJSONを生成している。CSS Animation と比較して、JS から細かく制御できるので今回の要件に合っている。ただモダンブラウザでもほとんど実装されてないので、ポリフィルを使っている。ポリフィルでだいたい動く。
吐き出したJSONをこういう風に食わせると動く。
const timelines = [{...}]; for (const tl of timelines) { const { keyframes, ...others } = tl el.animate(tl.keyframes, others) }
UIは手打ちSVG
今後
スコープを限界まで小さく、本当に単機能なものなら作れる…かもしれない。が、本気で作ろうとした場合のだるさも既に見えている。とくにドラッグアンドドロップでアンカー移動とか考えると辛い。レンダリングの最適化のことも考えると頭が痛い。
金もらってるわけじゃないし、気分が乗ったら作るかもしれない。
ところで Patreon を募集しております。
Redux 再考
今まで自分で作ったものが十数個、仕事で5社ぐらいの redux を見てきたので、その結果思うところを書く。
前提として、自分はエコシステムに乗るという意味で今では redux 肯定派だが、redux それ自身が過剰に抱えている複雑さはもっと分解されるべきだ、という立場。
Redux がうまく設計されているとどうなるか
- 一貫した一つの設計論に従うので、考えることがなくなる
- 難しさが廃されるのではなく、難しい部分が一箇所に集中する。React Component の末端では、何も考えることがなくなる。状態管理という難しい部分を作る人と、末端のコンポーネントのデザインに注力する人を分けられる。
- 大規模になっても設計が破綻しにくい、というエンタープライズ向きな特性を持つ。が、その技術基盤は(静的)関数型由来の考えが多く、基礎設計や基盤理解にはハイスキルが要求され、需要と適用対象のミスマッチを感じることはある。結果として、そもそもハイスキルを前提として、大規模であることが自明な SPA 向きということになる
現実の Redux はどうなっているか
- 「実際に起こること」は大したことがないが、「物事が起こる経路」が難しい。教える側とすると、関数型由来の概念ばかりで、説明するコストが高い。そもそも redux そのものが elm 由来で、 React 自体も関数型的 API デザインの傾向があり(不変性を根拠にした差分アルゴリズム)、 Redux はさらに過激に関数型由来の概念を必要とする(reducer という 実質 State Monad 的な何か, 副作用の分離、様々な関数合成、関数を返す関数、高階コンポーネント、etc...)
- Middleware に何を使うかで、 redux ユーザー同士の非同期のノウハウは共有できず、分断されている(thunk, saga, steps, epic, no middleware)
- 初学者にとって、 初期ボイラープレートが大仰で印象が悪い。巷にあふれるチュートリアルも、悪印象を助長するものが多い。ボトムアップに学ぶ人には、最終的な形態を最初に見せる必要はないと思うのだが…
- 現実問題、「それ本当に redux が必要?」という問いに、答えを窮する採用事例が多い。React Native や Electron のような SPA ではわかりやすく必要と言えるが、普通のウェブサイトに大仰な Flux が登場しうるかは、局所的な複雑度がどれほどかによる
- 静的関数型由来の概念が多いくせに、TypeScript / Flow での型付けが困難な API、という実用上の問題を抱えている(redux.combinerReducers)
- サーバーサイドの人が使うと、DB 側のテーブル定義に従って reducer を分割しすぎる傾向がある。このせいで複数の reducer の中身を跨ぐ処理が書きづらい問題と相まって、結果として使いづらく感じる、という自滅傾向をよく見る。個人的には reducer は画面に対し一つで、あとで段階的に分割するほうがいいと思う
- 他の Flux フレームワークはほぼ全滅したので、選択肢は実質 redux or 我流の 2 つしかないのが現実。エコシステムに乗る、採用と教育コストを下げる、Web の人間を ReactNative に耐えうる設計をできるようにトレーニングする、という点で、それ自体の必要性が薄いが redux を採用するというのは、実際ある。
- SPAという技術そのものを目的にすると失敗する。ただ、あらゆるプロダクトチームは、自分たちのプロダクトに求めるUXを過大に設定する。だからこそ会社が興ってプロダクトがあるわけだが、外からは滑稽に見える。これは技術とビジネスの本質的な問題。
今後も主流であり得るのか
- redux の作者でありオピニオンリーダーだった Dan Abramov は、現在 redux との距離を置いているように見える。React コアチームに近い、よりシンプルなものを、という立場になっている
- 実務上優秀なライブラリと、普及させたい側にとって都合がいいライブラリは異なる。難しい概念を振り回す redux が React 側に疎まれてるんじゃないか、と感じることがある。例えば react-training 社の react-router が、簡単側に倒してAPI削りすぎて不興を買ってる
- React 公式チーム的には HoC より render prop 推しで(New Context API の実装 example がそう)、 Dan Abramov もその気配がある。他に、GraphQL ライブラリの apollo の React バインディングなどの実装でも redux の関与を減らすような、それ自身で非同期や状態管理を行う render prop ベースの API が実現されており、 Redux 不要論の根拠の一つになっている
- React v16 の New Context API そのものは Redux を倒すものではなく、むしろ Redux を効率的に実装するための手段なのだが、「状態をビューにマッピングする」という概念自体を再考する段階で、別のものが出てくる可能性もある
- React v17 で React 自体が非同期処理の仕組みを持とうとしている(Suspense)が、非同期を簡単に書くためのツールとして使いたい側と、CPU パフォーマンスが良くないときのパフォーマンス向上に注力するための非同期というコアチームで、既にミスマッチがある。ただ非同期処理のやり方が固まってくると、 redux 側の設計指針も変わってくるだろう。
- 現状 redux を超える React の設計論はないが、React v17 でContext, Suspense 込みで再考されるときに、新しい設計論がまたいくつか出てくるはず
React から見た Vue 周りのエコシステムについて
- Vue は React 界隈で枯れた概念をコアチームに近い人たちが実装する傾向があり、良き二番煎じという振る舞いがうまい(Redux => Vuex, Next => Nuxt)。Facebook は基本的にコミュニティのライブラリを公認しない結果、エコシステムの主流が定まらずに混乱する傾向がある。特にルーター周辺。社内ではチームごとに好き勝手にやってる様子。
- React / Redux の関数型的な不変性が厳しい世界からみると、Vue / Vuex の状態管理はかなり怠惰で弛緩しきってるように見える。学習には容易だがスケール時の不安がある。(みたいな話を @potato4d とした記憶がある)
- ユーザー基盤から見ると、英語圏 vs 非英語圏という構図が見え隠れしている。本体周辺は英語ドキュメントがあるが、Vue の周辺ライブラリは中国語のドキュメント / Issue / バグ報告しかないことも多いのが、個人的に採用を躊躇う要素
- React は難しいが一貫している(Simple)のに対し、 Vue はいろんなことが簡単にできるが一貫性がない(Easy)